
MDS Newsletter #39

Hey Folks,
Hope you had a great start to the week because we sure did as our 1st story about Amazing people in data is live!!!
We have many more stories lined up for you so keep following MDS!😄
Amazing people in data
Meet our very first guest, Vladyslav Hrytsenko: who started his career building software products, is an engineer at heart, and is now building data solutions in his role as CTO of Mighty Digital. We had a candid chat with him on his journey from the software world into the data world, which is truly fascinating.
Read the full story here.

If you know anyone that we should be speaking with for this series - Do let us know!
Interesting launch this week
How much time have you wasted on searching the required SQL syntax on google or stack overflow? I'm pretty sure, it's a lot!
Rasgo recently launched this super cool tool: SQL Generator, a browser tool that enables anyone to generate a complex SQL query without writing a line of code.
The SQL Generator tool will generate the SQL you need in copy/paste form, saving up a lot of time that can be used for data analysis. Do give it a try!
Here's a blog explaining how the SQL Generator works
Featured tools of the week
- Y42 is a full-stack data platform that anyone can run taking away the complexity of managing multiple tools. Create a scalable data platform and have a great time doing it.
y42 has raised a total of $33.9M in funding over 2 rounds. Their latest funding was raised on Oct 25, 2021 from a Series A round. - Avo is next-generation analytics governance. We’re changing how product managers, developers, and data scientists plan, track, and govern analytics across organizations.
Avo has raised a total of $4.5M in funding over 5 rounds. Their latest funding was raised on Sep 3, 2020 from a Seed round.
Featured data stack of the week
PingCAP is the company behind TiDB, an open-source, distributed, NewSQL database that supports hybrid transactional and analytical processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
Check out how they are building their data stack
Want us to feature your data stack? Add it here.
Good reads and resources
- Debezium to Snowflake: Lessons learned building data replication in production: Learn how Shippeo, a real-time transportation visibility platform, uses Debezium and Apache Kafka for replicating transactional data to Snowflake. Omar Ghalawinji, Cloud Data Engineer at Shippeo has written a blog about what to do and what not to do if you want to go beyond a simple PoC of these technologies to the actual implementation of a reliable system in production. He discussed optimizing Kafka usage in advance, creating an independent Debezium connector for each downstream system, and some of the major bugs countered during the process.
- Learning Curve of Data Governance: Only recently has data governance appeared as a priority with regard to the myriad of complex systems created. But still, data governance is often reduced to isolated documentation initiatives with little impact. In this article, Justine Nerce helps you understand what data governance is in practice by taking you on a journey through the data governance learning process each company inevitably experiences. She explained the whole data governance journey into 4 different stages; Unconscious Incompetence, Conscious Incompetence, Conscious Competence, and Unconscious Competence.
Journal
- 5 challenges Data Teams face supporting PLG revenue teams and how to address them: PLG introduces a lot of new data about how customers are using the product that not only GTM teams but sales, marketing, customer, and revenue teams can leverage. But this data also has its own set of challenges. In the latest MDS journal, Diana Hsieh discussed 5 common challenges that the PLG data team faces and what can be possible solutions to them. Lastly, she suggested picking one important business challenge that aligns with a top-line goal and solving all the problems vertically.
Community Speaks
This week's question: What’s that one thing you wished dbt had?
You can send your answers here
Last week's questions: What data engineering practices you will recommend bridging the gap between data producers and data consumers?
To bridge the gap between data producers and consumers, we should see this from a social and technical perspective. Social: be a "people" person with data consumers. Don't get into the technical details. They don't care. Ask them about the problems and questions they have. Keep asking why, why, why! Almost like a therapist. Be a "geek" with the data producers and manage the conversation towards what the consumers care about in order to keep technical focus and avoid boiling the ocean. Technical: with data consumers, data modeling and knowledge management is key. You should be able to translate what the consumer is saying and draw it on the white board, and push into the details of the semantics (what does X really mean). You should be able to manage meetings with different stakeholders, and integrate the results and present them to a wider group. With data producers, you need to ground the semantics from the data models into the reality of the data....
-Juan Sequeda, Principal Scientist at data.world
Read the full answer here
Upcoming data summits and events
- Modern Data Stack meetup is getting organized in France on June 27, 2022
Theme: from Hadoop to the modern data stack.
Register now to learn ingestion, transformation, warehousing, analytics, orchestration & observability of data. - Databricks is organizing "Data + AI Summit" in San Francisco on June 27 -30, 2022.
The rise of the data lakehouse paradigm means every organization now has a new destination for data. As the world’s largest gathering of the data and analytics community, Data + AI Summit helps chart the path to get there. Register here.
Data startup funding news
- Pocus, a Product-Led Sales platform based in San Francisco, has raised a $23 million Series A round of funding!
This round of funding was led by Coatue, First Round Capital, and Box Group. Pocus is also backed by an impressive list of angel investors, including Adam Blitzer (COO, Datadog), Akshay Kothari (COO, Notion), Scott Belsky (CPO, Adobe), and many others.
Link to the announcement. - Validio Data, a data quality platform, raised $15M in a seed funding round!
This round of funding was led by Lakestar with participation from J12 and a list of renowned angels; Zlatan Ibrahimović, Denise Persson, Kevin Ryan, Emil Eifrem, Mehdi Ghissassi, Kim Fai Kok and Dara Gill.
Read the full story here.
MDS Jobs
- Sunrun is hiring a 'Director, Data Integration’
Location- USA
Data Stack: Snowflake, dbt, Tableau
Apply here - Nearmap is hiring a ‘Senior Data Analytics Engineer’
Location- Sydney, Australia
Data Stack- AWS, Fivetran, Snowflake, dbt, Airbyte, Looker
Apply here - Unchained Capital is hiring a ‘Senior Data Engineer’
Location- USA
Data Stack- dbt, Postgres, Metabase, AWS
Apply here
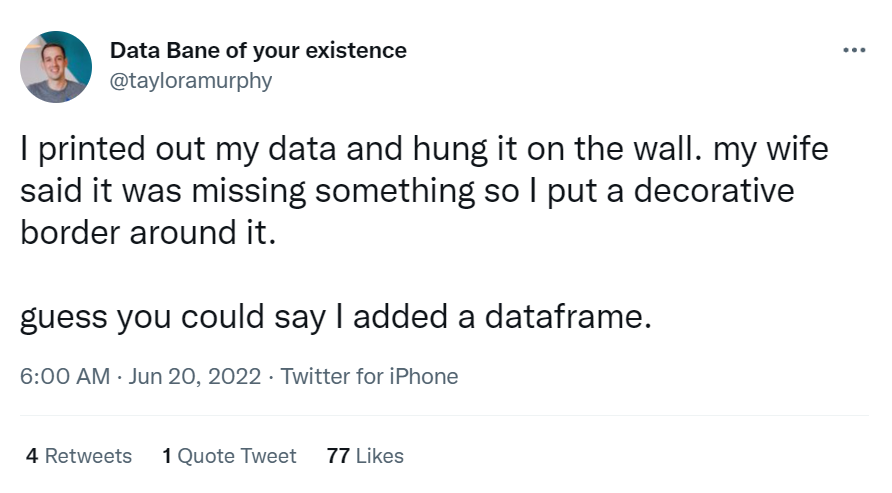
🔥 On Twitter

Just for fun😄
If you have any suggestions, want us to feature an article, or list a data engineering job, hit us up! We would love to include it in our next edition😎
Subscribe to our Newsletter, Follow us on Twitter and LinkedIn, and never miss data updates again.
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)