
MDS Newsletter #43

Hey folks!
In this edition you can find the Top 5 bookmarks for every data analyst, the reasons you should choose to self-host your data stack on Kubernetes, a virtual class for all you data nerds. And we meet Juan - this week's amazing person in data.
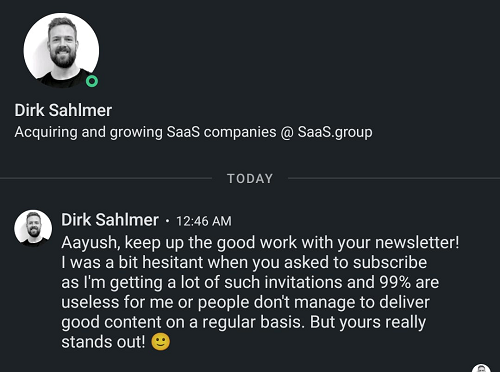
But first, some love from the community 💗
Amazing People in Data
Meet Juan: who turned his Ph.D. research into a successful company, Capsenta, and now is a Principal Data Scientist at data.world. He believes data management needs a paradigm shift and that shift is including social aspects of the business. In this interview we touched base on his journey, how the data scientist role has changed over time, the ABC of building data products, and the socio-technical approach to data. Read about his journey and his work which is as amazing as his podcast.

Featured companies of the week
- PostHog is an open source product analytics suite built for the modern enterprise, with the differentiators of being open source and having a broader view of the tools needed to make a product successful.
PostHog has raised a total of $27.2M in funding over 4 rounds. Their latest funding was raised on Jun 10, 2021 from a Series B round. - Mozart Data is the fastest way to set up scalable, reliable data infrastructure that doesn’t need to be maintained by you. Mozart Data’s all-in-one modern data platform empowers anyone to easily centralize, organize, and analyze their data without engineering resources.
Mozart Data has raised a total of $19.1M in funding over 3 rounds. Their latest funding was raised on Apr 27, 2022 from a Series A round.
Featured data stack of the week
- Aritzia is a vertically integrated design house with an innovative global platform. Aritzia is the creator and purveyor of Everyday Luxury, home to an extensive portfolio of exclusive brands for every function and individual aesthetic. Have a look at how leading fashion websites are organizing their data stack.

Good reads and resources
- Top 5 Bookmarks Every Data Analyst Should Have: Being a good analyst is all about balancing quality versus speed. Having a toolkit available that helps you cut corners without sacrificing quality is a certain way to improve your effectiveness. If you don’t currently have a bookmarks folder of “Tools,” this article by Josh Berry gives you a good starting point. He listed the Top 5 bookmarks that every analyst should have.
- Change Data Capture: What It Is and How to Use It: There are many ways to implement a change data capture system, each of which has its benefits. This article by Lewis Gavin will explain some common CDC implementations and discuss the benefits and drawbacks of using each. As he suggested “There is no right or wrong method to use. It all depends on the requirements for capturing changes and what the data in the target system will be used for.” Read this article to know more about the Push vs Pull strategy, different CDC mechanisms, and common CDC architecture.
Journal
- How to Build and Operate an Open-Source Data Stack on Kubernetes: The current data engineering ecosystem is filled with a wide range of tools from both open-source and third-party solutions. And to deploy a self-hosted open-source data stack you need to have the right tooling and processes in place. Michael Guarino has seen firsthand the challenges of deploying an open-source application on your own. But he realized it is valuable for organizations to self-host their data stacks to better navigate privacy and security concerns relevant to their field of work. In this journal, he wrote about the most common open-source tools to choose from at each layer of the data stack, why you should choose to self-host your data stack on Kubernetes, and three potential challenges he has seen when deploying an open-source data stack.
Upcoming data events and summits
- Atlan is organizing a virtual class for all you data nerds. Join "Masterclass by WeWork" on July 21 and learn about WeWork’s journey towards trust, transparency, and governance with Atlan, Snowflake, and dbt.
- On July 27th, Itay Katz, Idan Asulin and Julien Le Dem are organising an in-person event on ' The Future of Data Lineage'.
This meetup will focus on why data lineage is important for your environment, what are the common use cases, frameworks, and worldwide challenges, and a glimpse into the future.
MDS Jobs
- Hightouch is hiring a 'Data Advocate / Data Evangelist'
Location- US
Apply here
Know more about Hightouch here - CollegeVine is hiring a 'Senior Data Engineer'
Location- Remote, USA
Data Stack- Airflow, AWS, Kafka, Spark
Apply here - Replicated is hiring a 'Senior Analytics Engineer (Data)'
Location- Remote
Data Stack- dbt, Snowflake, Looker, Hex
Apply here
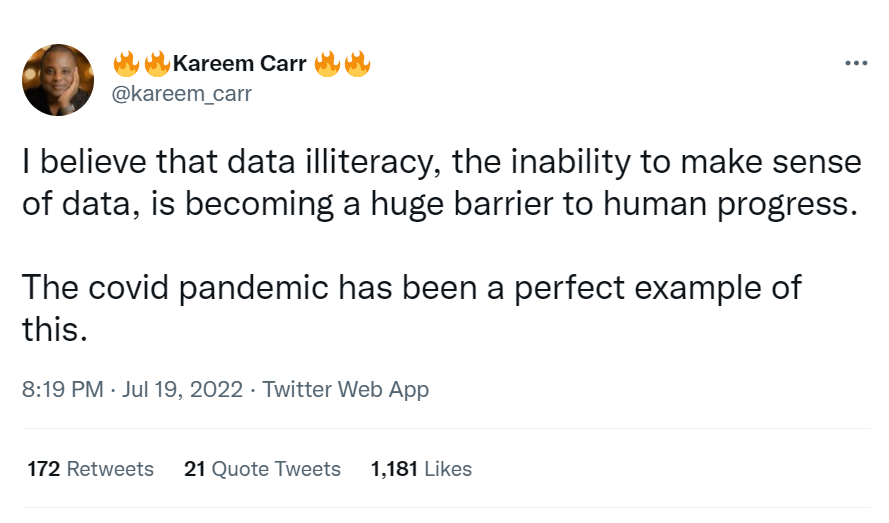
🔥 on Twitter
Just for fun😄

If you are enjoying this newsletter series please consider forwarding this to a friend! If a friend sent you this, get the next newsletter by signing up here.
What do you think about our weekly Newsletter?
Love it | It's great | Good | Okay-ish | Meh
If you have any suggestions, want us to feature an article, or list a data engineering job, hit us up! We would love to include it in our next edition😎
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)