
MDS Newsletter #54

While building a data product, you have to deal with many issues. What data is available to use, how to best use that data to meet the requirements, how to put this data product into production etc. In today's edition, find out how to build a data product that won’t come back to haunt you.
Modern Data Show S01 E04
Navigating the future of Modern Data Stack with Chris Riccomini: There is a lot of content out there about what the future hold for Modern Data Stack from a vendor's perspective, but very few about what is actually going to stay relevant in the market. To understand this, we have Chris Riccomini joining us for this week's episode on navigating the future of Modern Data Stack.

Featured tools of the week
- Nexla is a unified data operations company and its platform makes it simple for anyone to create scalable data flows. Teams working with data get a no/low-code unified experience to integrate, transform, provision, and monitor data for any use case.
Nexla has raised a total of $15.5M in funding over 2 rounds. Their latest funding was raised on Oct 13, 2021 from a Series A round. - Selfr is a plug & play data platform that empowers teams with limited data engineering resources to centralize, transform, and analyze data at scale.
Selfr is a low-code data platform that provides all the tools you need to go from your live data sources to interactive dashboards. It replaces stitching together a cloud data warehouse, an ELT solution, a data transformation solution, a scheduler, and a BI solution.
Featured data stack of the week
CLARK makes it easy to get properly insured and combines its industry-leading user experience with personalized and independent advice from insurance experts.
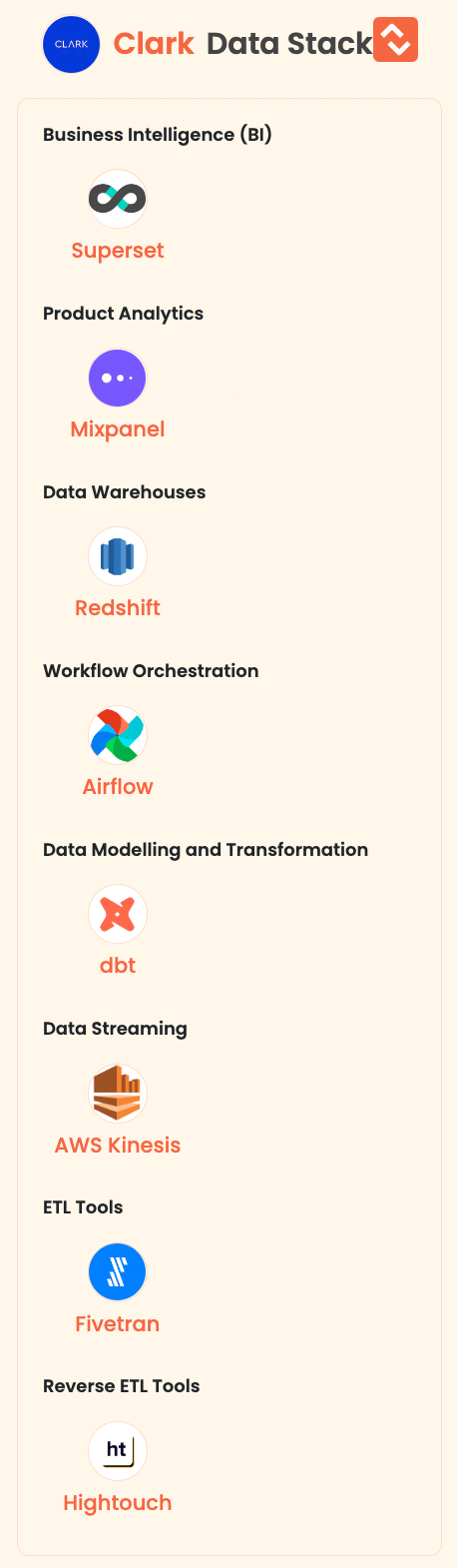
If you want us to feature your data stack, publish it here.
Good reads and resources
- Upgrading Data Warehouse Infrastructure at Airbnb: The engineering team at Airbnb upgraded their Data Warehouse Infrastructure from HDFS clusters to S3 to provide better stability and scalability. In this blog, Ronnie Zhu and the team briefly describe the current state of Airbnb data warehouse infrastructure and the challenges. They also share their learnings from upgrading one critical production workload: event data ingestion and how they saw more than 50% compute resource-saving and 40% job elapsed time reduction in the data ingestion framework with Spark 3 and Iceberg.
- Best Practices for Building a Cloud-Native Data Warehouse or Data Lake: Building a cloud-native data warehouse or data lake is an enormous project. Before you can even begin performance analytics and reporting a number of tasks need to be done like- data ingestion, integration, connectivity to analytics platforms, data privacy and much more. In the last part of 5 part series on Data Warehouse vs. Data Lake vs. Data Streaming, Kai Waehner writes about the best practices that must be applied to build a resilient, scalable, elastic, and cost-efficient data analytics infrastructure.
- How to Build a Data Product that Won’t Come Back to Haunt You: While building a data product you have to deal with issues of what data is available to use and how to best use that data to meet the requirements of the end-user and putting this data product into production is a challenge in itself. In this article, Marian Nodine shares 12 touch points and shares some of the considerations and the important concerns she addresses at each of these touchpoints, before releasing production reports, dashboards and models into the wild. Paying attention to these questions will help prevent you from getting bogged down in support and will give you more time to be creative and build new things.
If you have an interesting blog that you would like us to share with the data community, submit it here.
Upcoming data events and summits
- Join the Masterclass and an AMA with Michele Goetz (VP Principal Analyst, Forrester Research) on the Past, Present, and Future of Data Catalogs hosted by Atlan. Learn more and sign up here.
- Data Driven NYC is hosting a live, in-person event on October 11th at ADP Lifion with Ternary Data & Snowplow. RSVP
- Big Data and AI Toronto by Corp is being organised on October 6th & 7th, 2022 at Metro Toronto Convention Centre. Big Data and AI Toronto allow them to explore and discuss insights, showcase the latest innovative projects, and connect with other data and analytics professionals. Register here.
MDS Jobs
- Patagonia is hiring a 'Data Engineer'
Location: Amsterdam, Netherlands
Stack: dbt, Snowflake
Apply here - Drata is hiring an Analytics Engineer
Location: Remote
Stack: Snowflake, Fivetran, Sigma
Apply here - Sigma Computing is hiring a 'Modern Data Stack Solution Engineer'
Location: USA
Data stack: Snowflake, Databricks, dbt
Apply here
🔥 on Twitter

Just for fun 😃

Subscribe to our Newsletter, Follow us on Twitter and LinkedIn, and never miss data updates again.
What do you think about our weekly Newsletter?
Love it | It's great | Good | Okay-ish | Meh
If you have any suggestions, want us to feature an article, or list a data engineering job, hit us up! We would love to include it in our next edition😎
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)