
MDS Newsletter #68

Are you ready for an in-depth look into the latest developments in the field of Modern data stack? Our newsletter is here to keep you updated on the most innovative tools and data stacks, as well as provide expert analysis on current trends and developments. We also bring you information about exciting events, job opportunities, and more. Be sure to stay ahead of the curve by subscribing to our newsletter.
Featured tools of the week
- Correlated: Correlated helps SaaS companies like Intercom, Reveal, and LeadIQ deploy, test, and iterate on a Product Led Sales playbook that works. Correlated connects to 1st-party behavioral data including website visits, product usage, and billing data from Snowflake, BigQuery, or Redshift to power ML propensity models that tell our customers which users or accounts are most likely to convert from free to paid, expand revenue, be cross-sold into and more.
Correlated has raised a total of $8.3M in funding over 2 rounds. Their latest funding was raised on Aug 4, 2021, from a Seed round. - Mozart Data: provides the fastest way to set up scalable, reliable data infrastructure that doesn’t need to be maintained by you. Mozart Data’s all-in-one modern data platform empowers anyone to easily centralize, organize, and analyze their data without engineering resources.
Mozart Data has raised a total of $19.1M in funding over 3 rounds. Their latest funding was raised on Apr 27, 2022, from a Series A round.
Featured data stack of the week
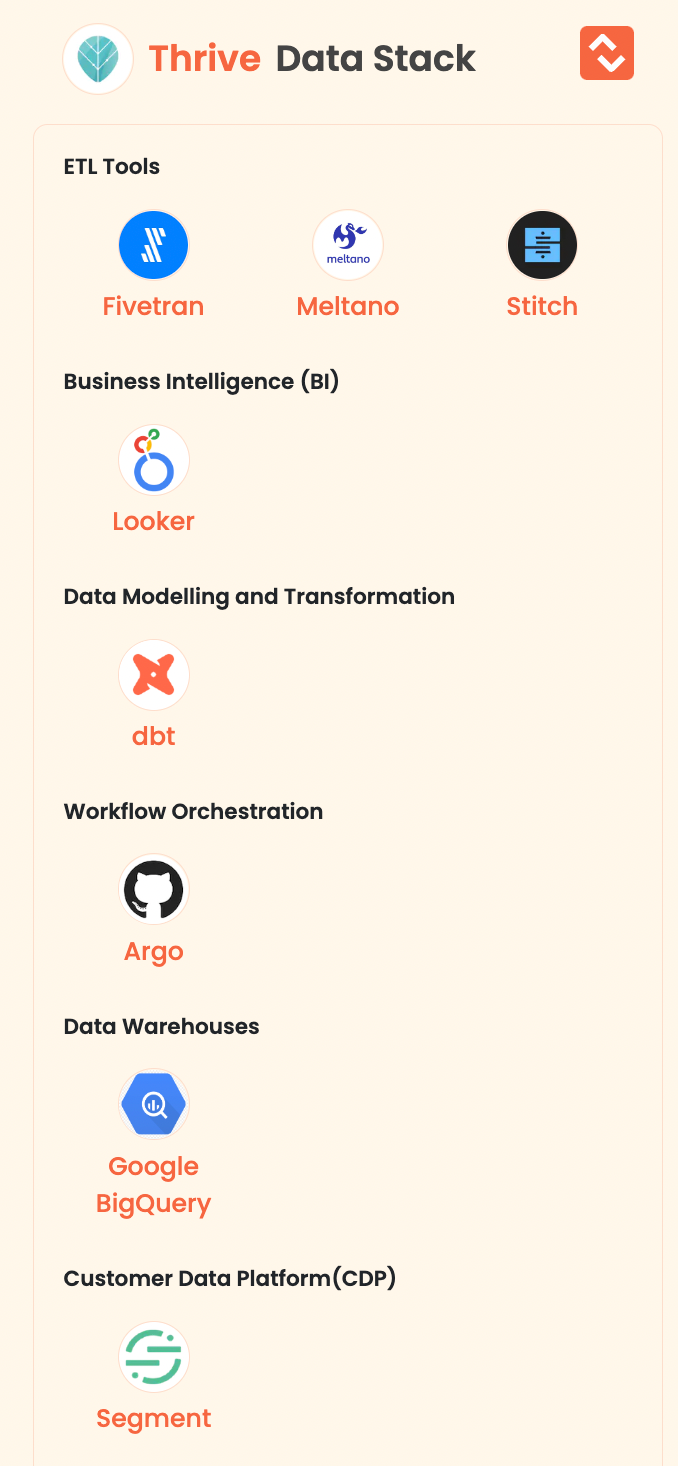
- Thrive: offers companies and individuals sustainable, science-based solutions to enhance both mental and physical well-being and performance, purpose, and relationship with technology. They are committed to accelerating this cultural shift around the world.
Here are the data tools of Thrive:
Good reads and resources
- Data Engineering Best Practices: Tech stack with PostgreSQL, DB, Airflow and Redash: This article is written by Yishak Tadele, he talks about the best practices for data engineering, specifically focusing on a tech stack that includes PostgreSQL, DB, Airflow, and Redash. He covers topics such as data warehousing, data pipelines, and the difference between ETL and ELT processes. He also discusses specific tools that are commonly used in data engineering, such as Airflow and DBT. A sample project is also provided in which a city traffic department wants to collect traffic data using drones and use it to improve traffic flow in the city. The goal is to create a scalable data warehouse to organize and store the data in a way that allows for easy querying and analysis in future projects.
- Design Document for Data Platforms: This article is written by Gaurav Thalpati who guides on creating an effective design document for a data analytics platform. It covers key sections that should be included in a design document such as background and overview, requirements, design considerations, data architecture, data governance, data quality, data storage, and data access, data processing and data integration, data security and data retention, testing and monitoring, and deployment and maintenance. Other sections such as test strategy, test automation, measure success, references, and appendix are also covered. The article provides examples of sections that should be included as well as some general guidelines for when and how to write the design document and maintain it throughout the project.
MDS Journal
- Data warehouse native applications: Data warehouse native applications are software optimized for working with large amounts of data and custom business entities, commonly used for data analysis, reporting, and more recently, for orchestrating sales processes and customer engagement. These types of applications help organizations to centralize and manage large amounts of data from various sources, and provide benefits such as improved data access, enhanced data quality, increased efficiency, and improved decision-making. Common applications of data warehousing include business intelligence, analytics, and customer segmentation, enabling organizations to identify trends, patterns, and relationships in the data and optimize business processes.
By Maxence de Villepion
If you also have an interesting blog that you would like us to share with the data community, submit it here.
Upcoming data events, webinars, and summits
- Join the virtual conference "DATANOVA" on February 8th and 9th, 2023, focused on driving business success with data. This event is tailored for professionals in leadership, analysis, and data engineering and architecture roles. Don't miss out on the opportunity to learn from industry experts and enhance your skills.
Register for the event here. - Join the virtual data event "Data Engineering Live Summit" on 18th January 2023 from 10:00 am - 4:00 pm (EST) hosted by Ai+ and ODSC to get insights from leading practitioners and learn about the latest development in data engineering tools and techniques.
Register for the event here. - Join the interactive session "Data Contracts: Experts Panel & AMA" by the DataHub community on Wednesday, January 18, 2:30 am - 3:30 am (IST). Speakers include Shirshanka Das (Co-Founder, of Acryl Data) and Chad Sanderson (Data Contracts Advocate, Founder of Data Quality Camp)
Register for the event here.
MDS Jobs
- Instacart is hiring a Senior Analytics Engineer
Location: Remote
Stack: dbt, Snowflake, Databricks, Mode, Airflow
Apply here - OneCare Media is hiring a Senior Analytics Engineer
Location: USA
Stack: dbt, Snowflake, Keebola, Sigmacomputing
Apply here - ConnectRN is hiring a Senior Data Analyst, Operations
Location: USA
Stack: dbt, Snowflake, Fivetran, Sigma
Apply here
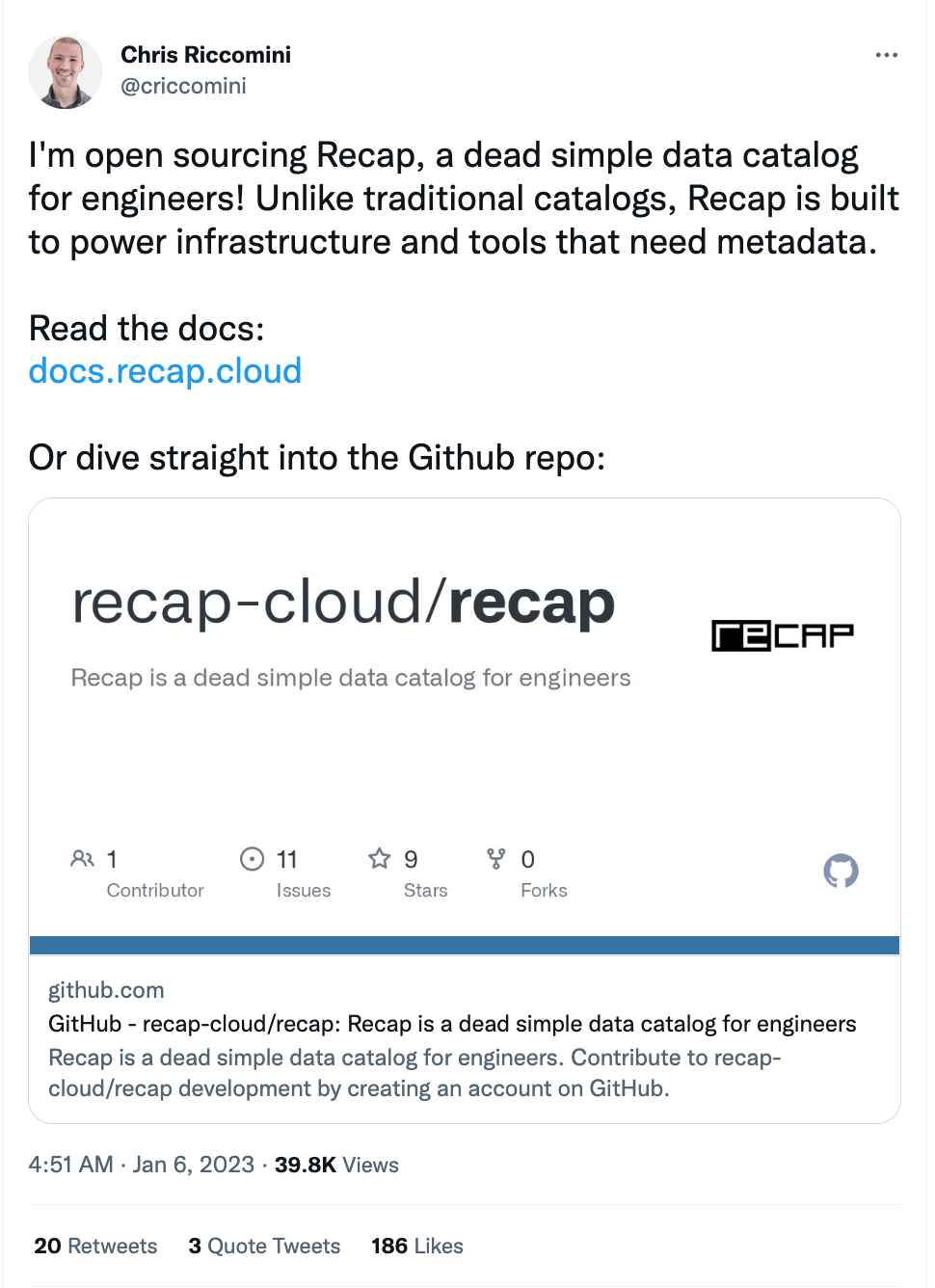
🔥 Trending on Twitter
Just for fun 😀

Subscribe to our Newsletter, Follow us on Twitter and LinkedIn, and never miss data updates again.
What do you think about our weekly Newsletter?
Love it | It's great | Good | Okay-ish | Meh
If you have any suggestions, want us to feature an article, or list a data engineering job, hit us up! We would love to include it in our next edition😎
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)