
MDS Newsletter #77

In this week's newsletter, learn the steps to use Docker Compose to integrate Kafka and S3 with Spark Structured Streaming and read how to apply the principles of chaos engineering to data engineering! And be sure to register for two fantastic data events taking place over the next few weeks!
Modern Data Show S02 E04
S02 E04: Legacy to Modern: Transforming Analytics Infrastructure with Ian Macomber, Head of Analytics Engineering & Data Science at Ramp: In this episode of Modern Data Show Ian Macomber discussed the company's approach to automating finance tools and building the next generation of finance through data-driven decision-making. Macomber emphasizes the importance of cross-functional collaboration and embedding the data team into every part of the product engineering process. He also highlights the need for data compliance and privacy to be invested in every day and not treated as a one-time effort. Macomber warns against "Layerinitis," where teams prioritize quick solutions over long-term effects, and advises celebrating the hardening of code and inviting people into codebases to teach them best practices.
You can listen to this episode on Spotify, YouTube, Google Podcast, Apple Podcast and Amazon Music.

Featured tools of the week
- GoodData Cloud is an analytics platform focused on the semantic layer, reusability of metrics, business user self-service, and a multi-tenant environment. Their approach relies on a semantic layer consisting of a logical data model and metrics written in our analytical query language.
GoodData has raised a total of $167.7M in funding over 13 rounds. Their latest funding was raised on Jul 27 2021, from a Debt Financing round. - Graphext handles, transform and analyze any kind of data. From unstructured text bundles; to financial datasets with missing values; to datasets packed with images - links - dates, or other value types. They capture data, enrich it and provide a powerful visual interface to find actionable insights about customers, markets and products.
Featured stack of the week
- Fanatics is a leading global digital sports platform, complete with offerings that excite fans and maximize the reach and presence of partners across the entire sports ecosystem. They operate more than 300 online and offline stores including an e-commerce business with all major professional sports leagues (NFL, MLB, NBA, NHL, NASCAR, MLS, PGA), major media brands (NBC Sports, CBS Sports, FOX Sports) and over 300+ collegiate and professional team properties.
Here are the data tools of Fanatics:

Good reads and resources
- Dockerizing Spark Structured Streaming with Kafka And LocalStack: This article is written by Tal Wanish who explains how to integrate Kafka and S3 with Spark Structured Streaming using Docker Compose, to create a simple Spark application that aggregates data from a Kafka topic and writes it to a Delta table on S3. He divides the article into three parts - coding the Spark application along with its integration test, Dockerizing the application, and Dockerizing its dependencies (Kafka and LocalStack). He assumes some familiarity with Spark Structured Streaming API, Docker, Scala, and dbt and provides a step-by-step guide on how to Dockerize the application and its dependencies to create an isolated environment for local development that fully integrates Spark, Kafka, and S3. He also provides the complete source code in the repository for extended study.
- The Chaos Data Engineering Manifesto: Spare The Rod, Spoil Prod: This article is written by Shane Murray who discusses how the New York Times recently conducted a "premortem" exercise, intentionally introducing points of failure within its systems to test thresholds and improve resilience. The exercise was based on the concept of chaos engineering, which involves deliberately causing failure within a system to better understand its limits and strengthen it. While chaos engineering is not a common practice within data engineering, Shane suggests that data teams need to focus on building and maintaining reliable data systems at scale. He proposes applying the principles of chaos engineering to data engineering to improve data observability and ensure critical operations are not compromised. It involves having a bias for production but minimizing the blast radius, understanding it is never a perfect time to test data, formulating hypotheses, identifying variables at the system, code and data levels, bringing everyone into one room, and making it a regular occurrence. The laws are designed to stress test data systems and to help teams to better understand and prevent data incidents.
Upcoming data events, webinars and summits
- Join the physical event 'Data Council Austin 2023' in Austin, US from March 28th - 30th, 2023, where data's most influential makers, doers, and thinkers gather to shape the future of data innovation at every layer of the stack. If you’re a technical professional who wants to learn about new tools, architectures and best practices for building & implementing data systems, you want to be here.
Register for the event here. - Join the physical event 'Data Engineering Summit 2023' in Bengaluru, India from April 27th - 28th, 2023, which will feature a range of presentations, panel discussions, and workshops. The speakers will explore topics such as big data architectures, best practices for working with streaming data pipelines, and the latest technologies in the data engineering space.
Register for the event here.
MDS Jobs
- Zendesk is hiring Senior Data Engineer
Location: Poland - Remote
Stack: dbt, Snowflake
Apply here - Planet is hiring Analytics Engineer
Location: Germany, Remote
Stack: dbt, Bigquery
Apply here - Parker is hiring Data/Analytics Engineer
Location: New York City
Stack: dbt, Redshift, Airbyte
Apply here
🔥 Trending on Twitter
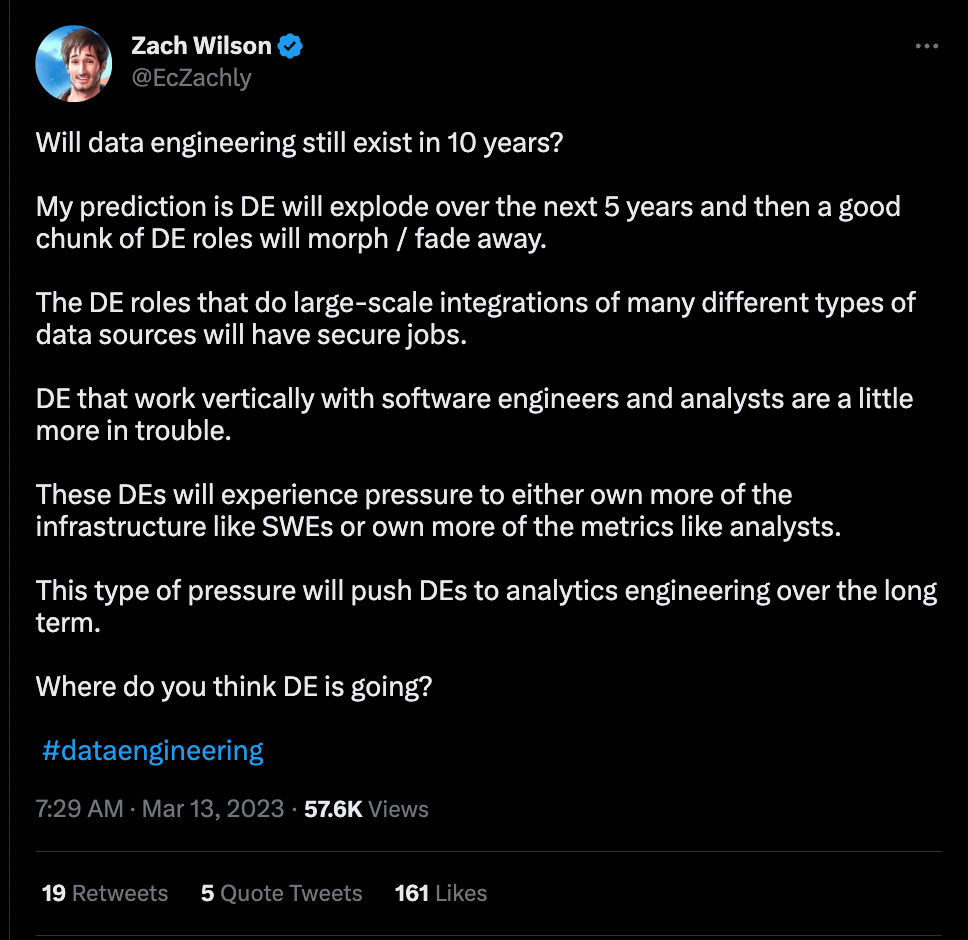
Just for fun 😀

Make sure you never miss out on the latest data updates by subscribing to our newsletter and following us on Twitter and LinkedIn.
We'd also love to hear your thoughts on our weekly newsletter. You can rate us here:
Love it | It's great | Good | Okay-ish | Meh
If you have any suggestions, articles you want us to feature, or data engineering job listings, please reach out to us. We're always looking for ways to improve and would be thrilled to include your input in our next edition.
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)