
MDS Newsletter #105

If you're a firm believer in continuous upskilling and the pursuit of knowledge from every possible source, then this newsletter is for you! In this week's issue, we're introducing you to two remarkable data events, one of which offers a chance to delve into the potential of generative AI and synchronized data.
Additionally, we've outlined the data stack of a data analytics tool with the capabilities of an expert data analyst. Scroll down to uncover what we've curated for you this week👇🏻📝
Featured tools of the week
- Superset: Apache Superset is a modern and user-friendly enterprise-level business intelligence web application. It's designed to efficiently process large volumes of data quickly and offers a wide range of intuitive options for users of all skill levels. Users can create various visualizations, from simple pie charts to intricate geospatial charts, to generate dashboards and reports that support business growth.
- Polytomic: Polytomic is a data-syncing tool designed for business systems. It enables integration with enterprise applications to synchronize internal data from real-time databases, warehouses, or spreadsheets into various platforms such as Zendesk, Freshdesk, Salesforce, HubSpot, Marketo, and Intercom.
Polytomic has raised a total of $2.4M in funding over 2 rounds. Their latest funding was raised on Feb 3, 2021, from a Seed round.
Featured stack of the week
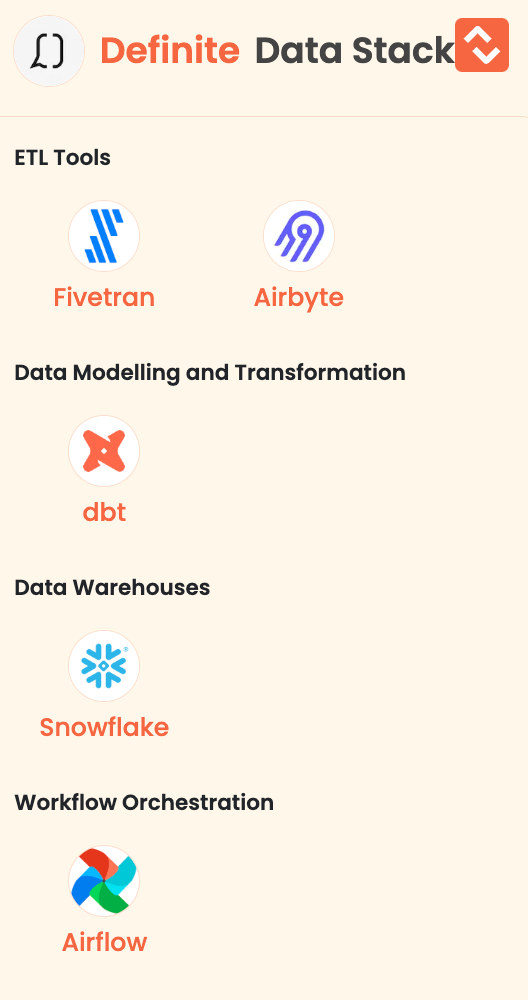
- Definite: Definite is a data analytics tool that acts like an expert data analyst. It consolidates all your data sources into one platform, offers natural language querying, enables fast iterations and visualizations, and reduces ad-hoc requests, freeing up your data team for more meaningful work.
Here is the data stack of Definite:
Good reads and resources
- Data Architecture to Data Engineers is like a roadmap is to a traveler: Data architecture is a foundational framework for data engineers to construct efficient, reliable, secure, and cost-effective data systems. It involves collaboration between data architects and data engineers to ensure the system aligns with organizational requirements. Pooja Jain explains the benefits of data architecture for data engineers include technology selection (e.g., databases or data lakes), efficient data pipeline design, normalized data models, and data governance implementation. Key questions addressed by data architecture encompass data handling, accuracy, technology choices, scaling, security, and monitoring. In summary, data architecture empowers data engineers to build and manage data systems that fulfil business needs, enhance performance, and enable informed decision-making.
- Data Engineering End-to-End Project — PostgreSQL, Airflow, Docker, Pandas: Dogukan Ulu describes a project that involves retrieving a CSV file from a remote repository, downloading it to the local working directory, creating a local PostgreSQL table, and writing the CSV data to this table using Python scripts. Afterwards, the data is extracted from the table, modified using Pandas, and used to create three separate data frames. These data frames are then used to create related tables in the PostgreSQL database, and the data frames are inserted into these tables. The entire process is automated using Airflow DAGs running in a Docker container. The project provides hands-on practice with Pandas and demonstrates an alternative way to store data locally while using PostgreSQL for data manipulation and storage.
Upcoming data events, summits and webinars
- Level up your data management with DoubleCloud - Join the upcoming webinar on
📅 October 4th
⏰ 14:30 IST
Level up your data management with DoubleCloud. Gain insights into the advantages of managed services versus self-management with DoubleCloud, and explore its suite of services, such as ClickHouse, Kafka, Transfer, and Visualization. Register here. - Experience the Future of Innovation at Possible Orlando, taking place from
📅 October 2 to 4, 2023
📍Gaylord Palms Resort & Convention Center, Orlando
It offers a unique opportunity to explore the transformative power of generative AI and harmonized data. This event promises to unlock new dimensions of innovation, creativity, and productivity in a rapidly evolving technological landscape. Register here today and be part of the revolution that fuels the future at Possible Orlando.
MDS Jobs
- Incident.io is hiring Data Engineer
Location: London, England
Stack: dbt, Fivetran, Metabase, Bigquery
Apply here - Digible is hiring Data Engineer
Location: US (Remote)
Stack: Python, Snowflake, dbt, AWS, Docker
Apply here - Loop is hiring Data & Analytics Engineering Manager
Location: Remote
Stack: Fivetran, dbt, Snowflake, Looker, Hex, Secoda
Apply here
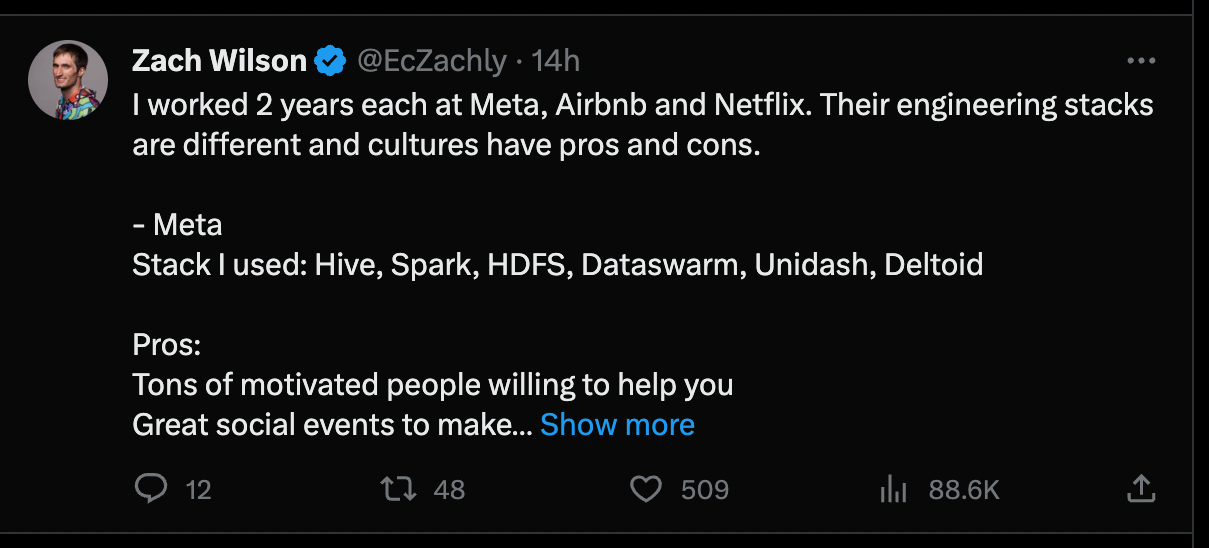
🔥 Trending on Twitter
Just for fun 😀

Are you always hungry for more information and updates about the ever-evolving world of data?
Well, you're in luck! By following us on LinkedIn and Twitter, you'll gain access to all the latest and greatest data content!
But wait, there's more! We want to hear from you - rate us here and let us know how we're doing.
Love it | It's great | Good | Okay-ish | Meh
We welcome any suggestions, articles you would like us to showcase, or data engineering job listings that you may have. Don't hesitate to get in touch with us at [email protected] and we would be delighted to incorporate your input into our next edition.
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)