
MDS Newsletter #104

Ready to supercharge your data game? We've cracked the code for building an unbreakable data platform! But that's not all - be sure to mark your calendars as an amazing data and AI conference set to take place in the beautiful city of Paris next week. Also, dive into the data stacks of a company that's changing the game for toll road drivers and helping them save both time and money, all thanks to the power of data. 💪
Featured tools of the week
- Preset: Preset is a cloud-hosted data exploration and visualization platform that leverages the open-source project Apache Superset™ to provide organizations with an accessible and scalable solution for data analytics. With a focus on open-source principles, Preset enables users to easily analyze data, create compelling visualizations and dashboards, and share their insights with teams.
Preset has raised a total of $48.4M in funding over 3 rounds. Their latest funding was raised on Aug 18, 2021 from a Series B round. - Plotly: Plotly is a data science and AI company focused on simplifying the integration of data science into business operations. They offer Dash Enterprise, a leading platform for building and deploying data applications in Python, enabling low-code development.
Plotly has raised a total of $18.4M in funding over 7 rounds. Their latest funding was raised on May 15, 2020 from a Series C round.
Featured stack of the week
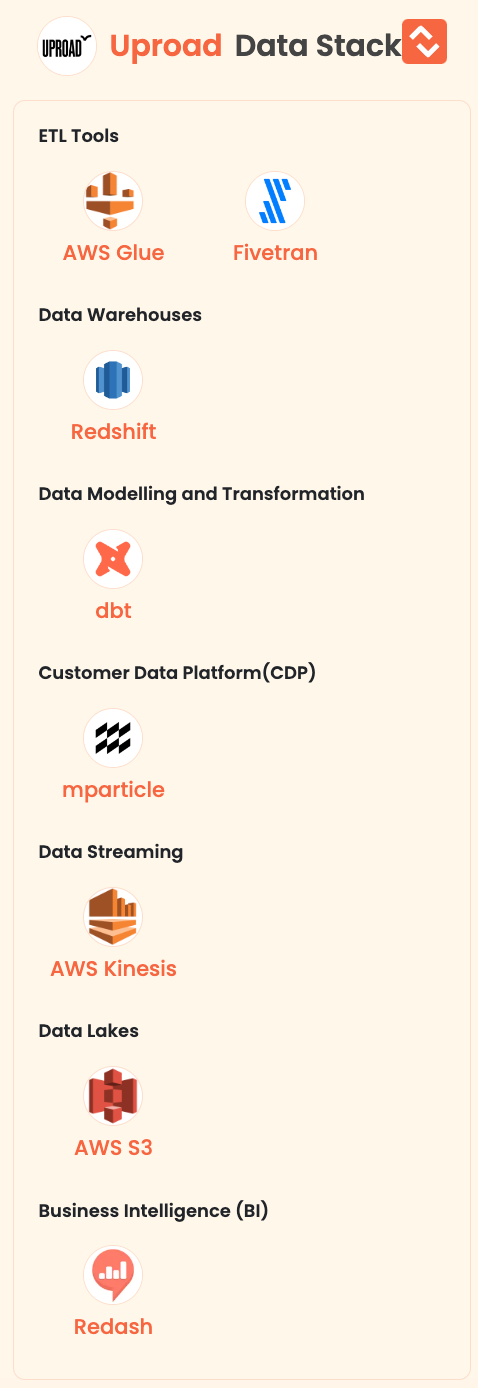
- Uproad: Uproad offers a mobile app designed to streamline toll road travel for users. The app provides several features, including cashless toll payments, the ability to skip cash lanes, real-time toll price alerts, and trip cost estimates. Uproad's mission is to enhance the toll road experience by providing transparency and convenience to drivers, allowing them to travel without uncertainty and save time and money.
Here is the data stack of Uproad:
Good reads and resources
- Principles of Data layers in Data Platform: Ever wondered how to build a rock-solid foundation for your data platform? Siva Ilango, the author of this article delves into the intricate world of data layers and their pivotal role in managing complex data systems. He explores the core principles of data layers within a data platform, underscoring their vital role in managing complex data systems. Ilango provides an in-depth examination of various data layers, including data ingestion, storage, processing, and presentation, elucidating how they collaborate to form a cohesive data platform. He also stresses the importance of factors like maintainability, scalability, and flexibility in platform design and how a layered approach facilitates these objectives. Additionally, he highlights the significance of sound data governance practices, encompassing data quality control and metadata management, in ensuring the reliability and effectiveness of a data platform.
- Unit Testing in Data Engineering: A Practical Guide: Unit testing, often underestimated in the realm of data engineering, emerges as a crucial practice for ensuring the reliability and accuracy of data pipelines and SQL data models. Beyond being a software development methodology, unit testing offers substantial value to data engineering by validating the correctness of individual components, ranging from Python functions in data pipelines to complex SQL queries. This article by Sam Zamany underscores the significance of unit testing in data engineering, emphasizing its role in guaranteeing high-quality data that can be trusted by data analysts, scientists, and decision-makers. Practical examples illustrate how to apply unit testing to data pipelines and SQL data models, and the integration of these tests into Continuous Integration (CI) pipelines is explored as a means to catch and rectify issues early in the development process. Ultimately, adopting unit testing and CI practices enhances data system reliability, fosters a culture of data trust, and ensures the handling of edge cases and errors with grace.
Upcoming data events, summits and webinars
- Join 'The Keynote' an event by Secoda on
📅 21st September
⏰ 2 P.M. ET
Dive into an electrifying journey into the future of the modern data stack! This event features data leaders like Tristan Handy, Chad Sanderson, Jordan Tigani, and Scott Breitenother. Don't miss this opportunity to redefine efficiency in modern data teams. Save the date and secure your spot here! - Big Data & AI Paris 2023, an event organized by Corp Agency, is set to captivate attendees with the very best of Big Data and Artificial Intelligence.
📍Palais des congrès de Paris, France
📅 25th and 26th September, 2023.
This two-day extravaganza offers an unparalleled opportunity for targeted immersion in the dynamic world of French Big Data and AI. Join Big Data & AI Paris 2023, and be part of a transformative experience that promises to redefine the landscape of Big Data and Artificial Intelligence. Register here.
MDS Jobs
- Mercury is hiring Data Engineering Manager
Location: Remote US/ Canada
Stack: AWS, Snowflake, Python, SQL, DBT, ETL, Fivetran, Airflow
Apply here - Nstart is hiring Senior Data Engineer
Location: Stockholm (Remote)
Stack: SQL, dbt, Python, AWS, Git
Apply here - Livops is hiring Business Intelligence Analyst
Location: Remote - USA
Stack: SQL, Power BI, Snowflake, DBT, Python
Apply here
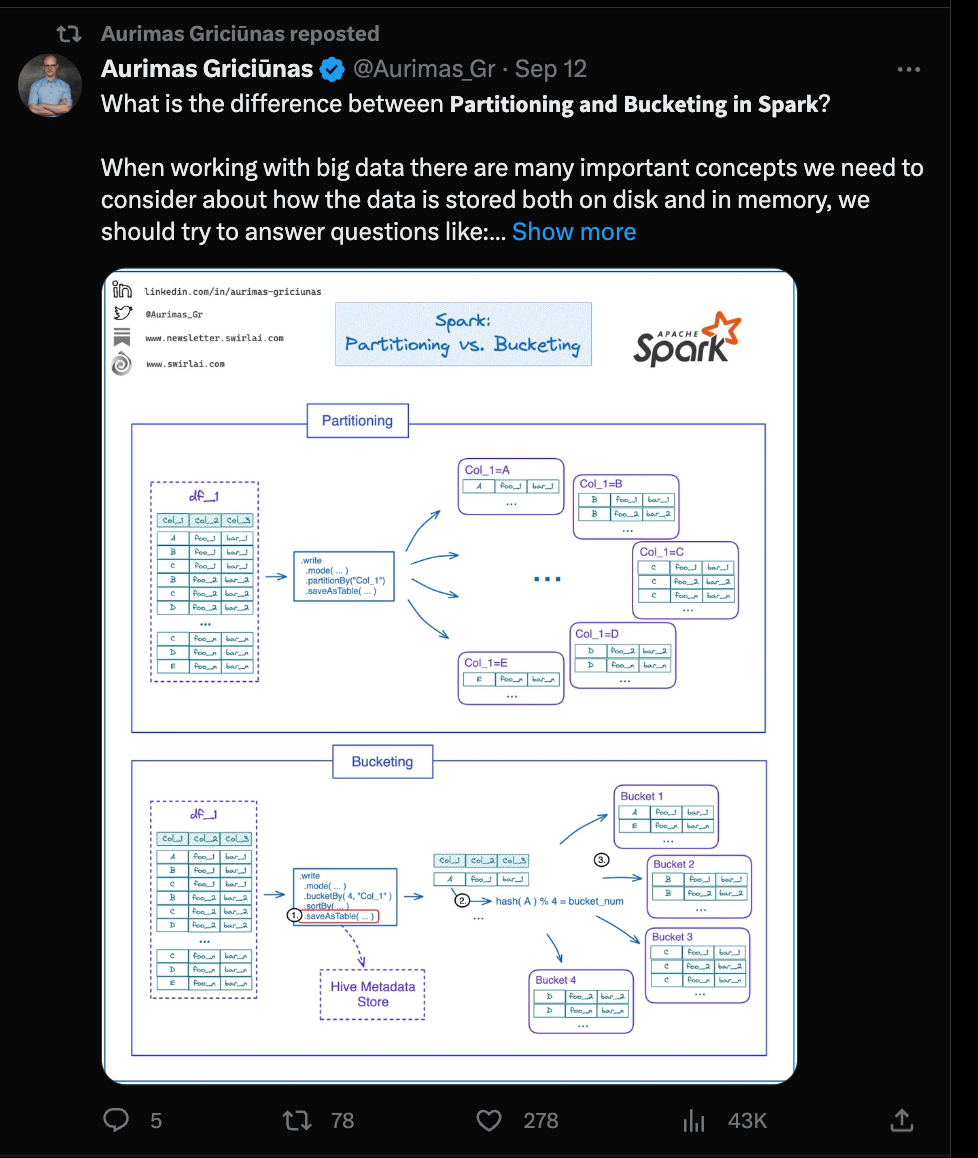
🔥 Trending on Twitter
Just for fun 😀

Are you always hungry for more information and updates about the ever-evolving world of data?
Well, you're in luck! By following us on LinkedIn and Twitter, you'll gain access to all the latest and greatest data content!
But wait, there's more! We want to hear from you - rate us here and let us know how we're doing.
Love it | It's great | Good | Okay-ish | Meh
We welcome any suggestions, articles you would like us to showcase, or data engineering job listings that you may have. Don't hesitate to get in touch with us at [email protected] and we would be delighted to incorporate your input into our next edition.
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)