
MDS Newsletter #103

Tired of manually transferring data back and forth between your different data warehouses and business tools? Well, we have great news for you - find an amazing data tool below that will make data synchronization a breeze - no code required. Plus, we've got links to two exciting summits for the Apache Pulsar and Apache Airflow communities. And for those of you looking to stay ahead of the game, don't miss out on an article discussing tips for improving your data governance practices. But that's not all - scroll down to find so much more!
Featured tools of the week
- HelloGuru: HelloGuru specializes in providing data synchronization services to connect data warehouses with popular business tools such as Salesforce, HubSpot, and Intercom. This is achieved through their software that enables users to build scalable, secure internal tools without needing to write any code. By syncing product usage data into the systems users already use, the company helps businesses obtain a holistic view of their customers, which can be used to improve their understanding of user behavior.
- Lightdash: It is an open-source Business Intelligence (BI) platform designed as an alternative to Looker. Lightdash is tailored for analysts and seamlessly integrates data visualization with modeling and transformation layers, creating a unified data metrics source for teams. It offers agile teams a rapid transition from dbt projects to a comprehensive BI platform, enabling analysts to write metrics and providing self-service analytics for the entire organization.
Lightdash has raised a total of $8.4M in funding over 3 rounds. Their latest funding was raised on Oct 6, 2022 from a Seed round.
Featured stack of the week
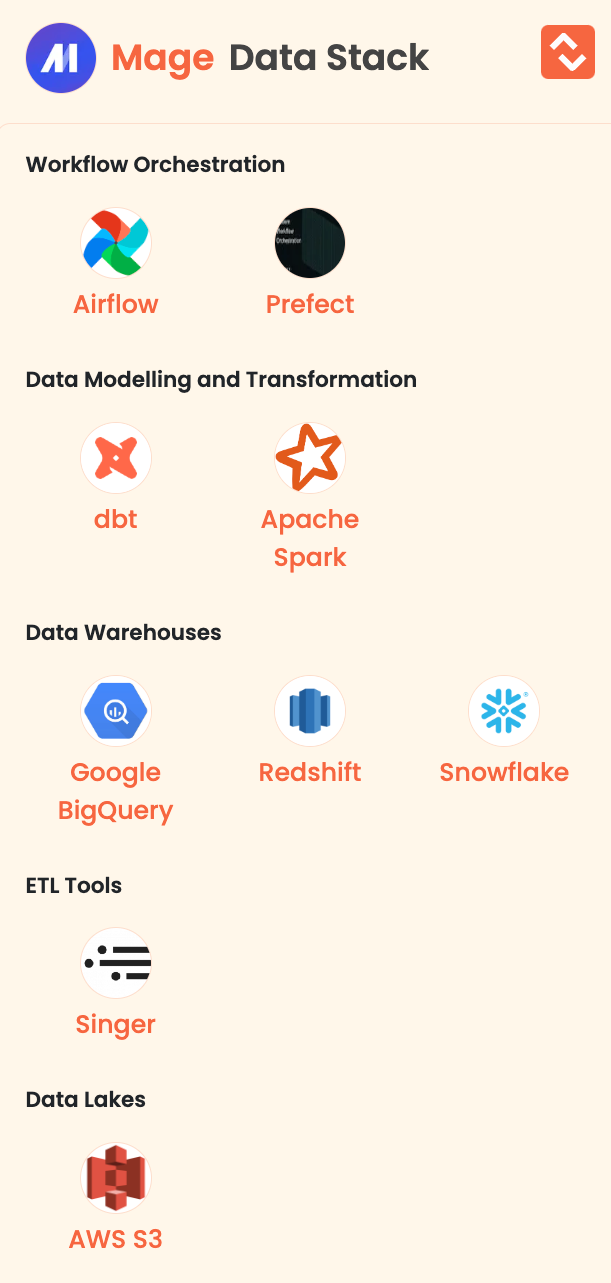
- Mage: It is an AI tool tailor-made for product developers. It addresses the challenge faced by developers who understand the potential of AI but lack suitable tools. Mage is an open-source hybrid framework that combines the flexibility of notebooks with the structure of modular code. Key features include data extraction and synchronization from third-party sources, real-time and batch data transformation using Python, SQL, and R, pre-built connectors for data loading into warehouses or lakes, and efficient pipeline management.
Here are the data tools of Mage:
Good reads and resources
- Knowing Your Data with OpenMetadata: Do you know how OpenMetadata can help you understand your data better and improve your data governance practices? Delve into this article by Sai Parvathaneni, who explores the key features of OpenMetadata, which include its ability to create a comprehensive and scalable data lineage, automate workflows, and ensure data trust. In addition to explaining the benefits of OpenMetadata, the article provides a step-by-step process for installing and configuring the platform. By using OpenMetadata, organizations can accelerate their digital transformation journey by easily finding, understanding, and using their data assets, resulting in faster time-to-market, increased operational efficiency, and more confident decision-making. OpenMetadata is a powerful tool for data teams seeking to enhance collaboration, transparency, and accountability, and improve their data management capabilities.
- 5 minute hacks to optimise data warehouse cost and speed(Snowflake, Bigquery, Postgres etc.): Unlock the secrets to supercharging your data warehouse performance and slashing costs and learn how Snowflake, BigQuery, and Postgres can revolutionize your data game with these 5 game-changing hacks by Hugo Lu. He explains how to optimize the performance and cost of a data warehouse using various tools such as Snowflake, BigQuery, and Postgres. It suggests five different hacks that can be implemented in just five minutes to improve the efficiency of queries, reduce query costs, and minimize storage costs. These include setting up automatic compression, reorganizing tables by clustering, caching, using smaller table scan ranges, and utilizing partition pruning. Hugo explains each of these techniques with code examples and diagrams to help readers understand how to apply them to their own data warehouse.
Upcoming data events, summits and webinars
- The Airflow Summit, an annual gathering for the global community of Apache Airflow enthusiasts, is set to return in 2023. This year's edition is scheduled to take place:
📅 September 19th to 21st
📍 Toronto, Canada
This community-driven, in-person event is a unique opportunity for Apache Airflow users and contributors to come together and share their knowledge and experiences. With a focus on collaboration and learning, the Airflow Summit promises to be an enriching experience for all attendees. Register here. - Pulsar Summit North America 2023 - Uniting the Apache Pulsar Community
📅 October 25, 2023
📍 San Francisco
This summit, hosted by StreamNative offers an action-packed one-day experience featuring keynotes, breakout sessions, and a networking happy hour with speakers from top companies like Google, AWS, Databricks, and ScyllaDB. It's the perfect opportunity for developers, architects, data engineers, DevOps professionals, and enthusiasts to learn about messaging and event streaming while connecting with Pulsar thought leaders in person. Register here.
MDS Jobs
- Simple Online Healthcare is hiring Analytics Engineer
Location: UK (Hybrid)
Stack: dbt, Snowflake, Metabase
Apply here - Addepar is hiring Senior Data Analyst - Product Analytics
Location: Pune, India
Stack: Looker, Snowflake / Databricks, MySQL
Apply here - SumUp is hiring Staff Analytics Engineer
Location: Paris (France) or Berlin (Germany)
Stack: dbt, Snowflake, Hightouch, Tableau, AWS
Apply here
🔥 Trending on Twitter

Just for fun 😀

Are you always hungry for more information and updates about the ever-evolving world of data?
Well, you're in luck! By following us on LinkedIn and Twitter, you'll gain access to all the latest and greatest data content!
But wait, there's more! We want to hear from you - rate us here and let us know how we're doing.
Love it | It's great | Good | Okay-ish | Meh
We welcome any suggestions, articles you would like us to showcase, or data engineering job listings that you may have. Don't hesitate to get in touch with us and we would be delighted to incorporate your input into our next edition.
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)