
MDS Newsletter #109

Diving into the complex world of Apache Airflow? Avoid these common traps with some practical tips under the reading resources. In today's edition, we have shared links to not one, not two, but three fantastic data conferences hosted by Rockset, Databricks, and Apache Flink, giving you the chance to learn, network, and discover the potential of these technologies. Inside you'll also find a company's data-focused way of helping entrepreneurs with financial help and support. And remember, there's much more to explore – so go ahead and read to find out more!
Featured tools of the week
- Mprove: It is an open-source company specialising in optimising processes within healthcare organisations. Their platform, combining Business Intelligence and Version Control, facilitates data analysts in creating SQL models, which can be explored via a self-service interface. The system not only expedites the Q&A cycle, but also inspires greater team collaboration. Mprove recognises the complexity of the healthcare sector, especially within the NHS, and aims to streamline operations, reducing delays to improve patient care. Their deployment is smooth and efficient, utilising Helm Chart for swift integration with Kubernetes environments.
- Hotglue: Hotglue facilitates the simplification of SaaS integrations through an efficient embedded iPaaS solution. The platform lets businesses build native API app integrations at a rapid pace, using its intuitive four-step process. Users can select data from Hotglue's extensive library of connectors, format it using their schemas or bespoke mapping scripts, choose their data reception method, and seamlessly embed Hotglue's components to enable a user-friendly account linking process. Moreover, with features such as detailed job logs, comprehensive reporting, and real-time alerts, Hotglue ensures businesses can effectively manage their integrations at scale.
Featured stack of the week
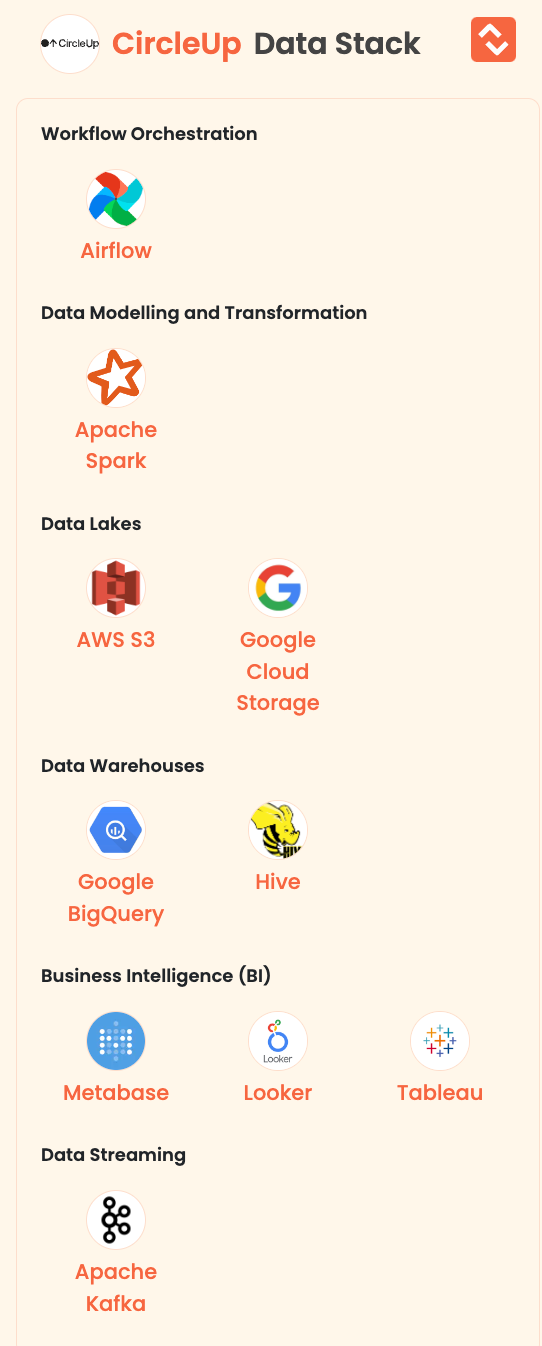
- CircleUp: CircleUp empowers entrepreneurs by providing funding and support. They use their Helio platform with data and machine learning to enhance decision-making for private companies. They also specialize in equity crowdfunding for social enterprises, especially Certified B Corporations, with a goal to fuel the growth of top businesses using data-driven insights.
Here is the data stack of CircleUp:
Good reads and resources
- How to Build Data Products?: This article is authored by Manisha Jain, Animesh Kumar, Shubhanshu Jain, and Samadrita Ghosh. They provide insights into how to build and deploy data products effectively. The authors emphasize having a clear understanding of the business problem and data available is crucial in developing a successful data product. They suggest a well-defined plan with incremental goals to avoid analysis paralysis. Also, the article emphasized the importance of working collaboratively with stakeholders to leverage their expertise and thus ensure the final product meets the business needs. Finally, they highlight the significance of monitoring the performance of data products and utilizing learnings to improve their functionality.
- Mistakes I Have Seen When Data Teams Deploy Airflow: Navigating the dynamic world of Apache Airflow can be tricky, so let's dodge the pitfalls and learn from the experiences shared in Ben Rogojan's enlightening Medium post about common mistakes when deploying Airflow. Ben describes common pitfalls data teams may encounter when using Apache Airflow. He enumerates several common mistakes such as overcomplication, not setting up a robust monitoring and alerting system, improper task dependencies, and improper use of operators. Ben suggests that teams should carefully consider their choices in terms of design, simplicity, regular checks, and the use of appropriate operators in Airflow to enhance efficiency and save time in the long run.
Upcoming data events, summits and webinars
- Rockset is hosting the Index conference, a pivotal forum for engineers dedicated to building search, analytics, and AI applications at scale on
📅 Thursday, Nov 2nd, 2023
⏰ 9:30am - 4:35 pm PT
📍 Virtually and in-person in Mountain View, CA
The event brings together diverse perspectives; including open-source tools users, those building their own infra in-house, and proponents of cloud-native and serverless technologies. Beyond networking opportunities, participants can immerse in detailed discussions about improvements in search and analytics systems, AI and vector databases, streaming data infrastructure, and cloud and serverless advancements. Register here. - The Apache Flink® Conference, more commonly known as Flink Forward, stands as a premier gathering for the Apache Flink and stream processing communities. Conference details:
📅 November 6-8, 2023
📍 Seattle, Washington
Organized by Ververica, the original creators of Apache Flink®, the conference caters to new and experienced users, core Flink committers, and thought leaders to share experiences, best practices, and insights in stream processing, real-time analytics, event-driven applications, and managing Flink deployments in production. Register here. - The Data + AI World Tour hosted by Databricks invites participants to help shape the future of data and AI. Details here:
📅 November 7th, 2023
📍 Munich, Germany
This event aims at offering insights into the latest advancements, showcasing real-world case studies, and proposing best practices essential for data and AI transformation. Attendees will unravel the potentials of technologies such as Databricks Lakehouse Platform, LLMs, Apache Spark™, Delta Lake, MLflow, and more through a series of inspiring keynotes, practical demos, and insightful sessions. Register here
MDS Jobs
- GrowthLoop is hiring Analytics Engineer
Location: Remote
Stack: dbt, Snowflake, Bigquery, Airflow
Apply here - ERGO Group AG is hiring Senior Data Engineer
Location: Humburg, Germany
Stack: Hadoop, Spark, AWS, Airflow, dbt
Apply here - Valon is hiring Senior Data Engineer
Location: New York, US
Stack: GCP, Fivetran, Segment, dbt, Bigquery, Looker
Apply here
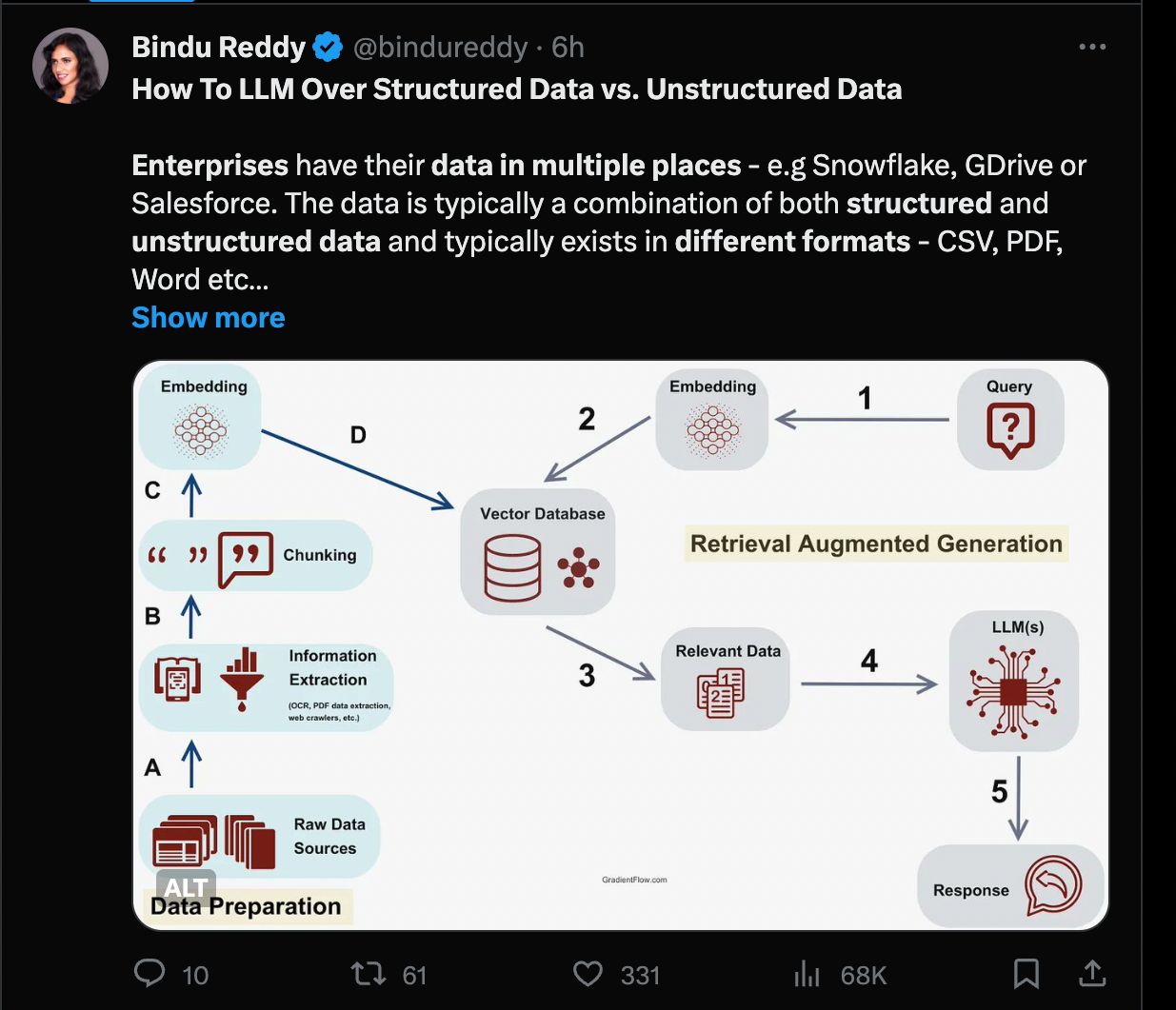
🔥 Trending on Twitter
Just for fun 😀

Are you always hungry for more information and updates about the ever-evolving world of data?
Well, you're in luck! By following us on LinkedIn and Twitter, you'll gain access to all the latest and greatest data content!
But wait, there's more! We want to hear from you - rate us here and let us know how we're doing.
Love it | It's great | Good | Okay-ish | Meh
We welcome any suggestions, articles you would like us to showcase, or data engineering job listings that you may have. Don't hesitate to get in touch with us at [email protected] and we would be delighted to incorporate your input into our next edition.
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)