
MDS Newsletter #52

In this week's edition learn all about the third wave of data technologies, ensuring maximum ROI on self-serve BI, improving data reliability within organisations and how can businesses make the life of data leads easy.
The Modern Data Show
S01 E02: The third wave of data technologies with Mahdi Karabiben: The data space has grown rapidly in the last few years. To put this progress in context Mahdi has divided it into three waves. First being of ETL, OLAP, and relational data warehouses. The second being the era of scalability and now we have entered the third wave - the Modern Data Stack wave. Join us in this interesting conversation where Mahdi talks about various aspects of Modern data stack like ETL, CDC, data obvervability and much more.

You can also listen to all the episodes on Apple Podcast, Spotify, Google Podcast, YouTube and Amazon Music
Featured tools of the week
- DoubleCloud is a platform that helps you build sub-second analytical applications on proven open-source technologies like ClickHouse® and Kafka®. It is the perfect solution for any industry if you are looking to unlock the potential of your data.
Founded in the year 2022, DoubleCloud is headquartered in Berlin . - Preset is a cloud-hosted data exploration and visualization platform built on top of the popular open-source project, Apache Superset™. Preset's fully managed service makes it easy to run Superset at scale with enterprise-ready security, reliability, and governance, enabling your entire organization to quickly and easily draw insights from your data.
Preset has raised a total of $48.4M in funding over 3 rounds. Their latest funding was raised on Aug 18, 2021 from a Series B round.
Featured stack of the week
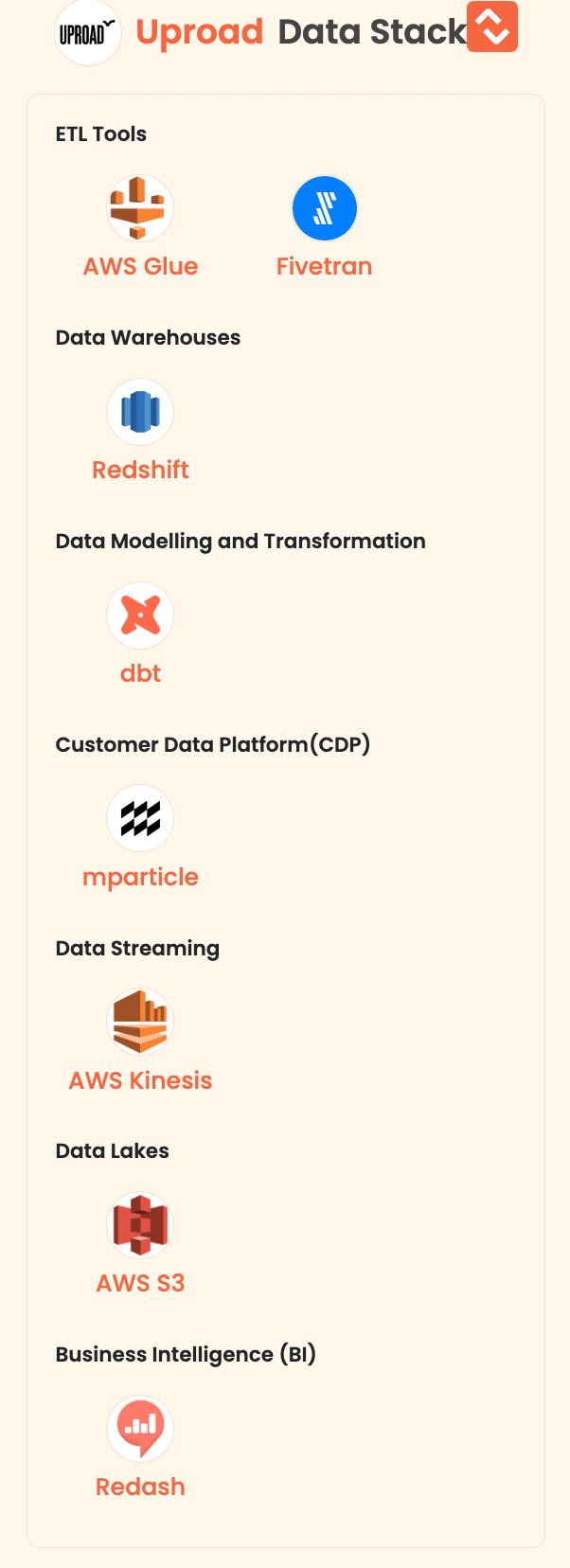
- Uproad allows you to use toll roads, skip cash lanes and conveniently pay tolls as you go. Also, you'll get informative toll price alerts and smartly plan your route with trip cost estimates. All so you can get where you're going without a bump in the road.
Here's how their data stack looks like
Good reads and resources
- Why does Self-Service BI Fail and What could Enterprises Do to Turn the Tide?: Self-serve BI is a gold ticket for organisations to achieve top-notch analytics and business can promptly generate analyses to make an informed decision on time. But does investing in Self -serve BI a key to becoming a data-driven organisation? There are a number of nuances which organisations have to keep in mind. While there are numerous advantages, one has to make sure that these advantages do not become pain points of applying self-serve BI. For example- using self-serve BI can help each team to create their own report, but creating these reports in abundance can also lead to overlapping analysis or different definitions to same the KPI. In this article, Anh Tran discusses how to remove these barriers and get maximum ROI from Self-Service BI.
- It’s Time to Set SLA, SLO, SLI for Your Data Team — Only 3 Steps: The key for organisations to make data-driven decisions is reliable data. For today’s data teams, the demand for real-time, accurate data has never been higher, but data reliability hardly gets full attention. Making correct decisions is challenging and it can only happen with highly reliable data. Treating data quality issues on an ad hoc basis will serve no good to data teams in long run. In this article, Xiaoxu Gao suggested businesses must implement SLA (Service Level Agreement), SLO(Service Level Objectives), and SLI(Service Level Indicators) concepts to help both data engineers and stakeholders deal with data reliability issues. These concepts are mostly applied to Software Engineering teams. But now, as data systems reach similar levels of complexity and importance in the organization, it’s time for the data team to apply the same concepts as well.
- The Difficult Life of the Data Lead: Data leads sit between the Head of data and the Individual Contributors. While the focus of IC is to deliver high-quality analysis and the Head of data is to build a great team and make sure the data team is working on the right priorities, Data leaders have to balance both these tasks. They do not just have to manage their team and stakeholders' expectations, but they also have to do hands-on jobs like building dashboards or delivering analysis. Their life becomes tough. Mikkel Dengsøe in this article writes about why data managers often find themselves managing all these tasks at once and what organisations can do on their end to make their job easier.
If you have an interesting blog that you would like us to share with the data community, submit it here.
Upcoming data events and summits
- Data.world is hosting its 5th virtual summit on Thursday, September 22, 2022.
This edition of the summit will focus on cutting through the noise to spotlight the role of social interaction and collaboration in the age of data. Explore how it takes people + technology working together to successfully enable DataOps, design for data mesh, build data products, and win with agile data governance.
Register for the event here. - Semantic Layer Summit 2022 is being organised on September 28th, 2022 featuring 30+ enterprise data leaders & top industry technologists.
Join this one-day virtual event where data leaders will explore the importance & impact of using a semantic layer for data & analytics. Hear from top data leaders, technologists, & industry experts on how to deliver actionable insights for everyone in your organization.
MDS Jobs
- Alma is hiring an 'Analytics Engineer II/III'
Location: USA
Stack: dbt, Looker, Redshift
Apply here - Patagonia is hiring a 'Data Engineer'
Location: Amsterdam, Netherlands
Stack: dbt, Snowflake
Apply here - GoPuff is hiring a 'Senior Analytics Engineer'
Location: US
Stack: dbt, snowflake, looker, sigma, databricks, dagster
Apply here
🔥 on Twitter
Just for fun 😃

Subscribe to our Newsletter, Follow us on Twitter and LinkedIn, and never miss data updates again.
What do you think about our weekly Newsletter?
Love it | It's great | Good | Okay-ish | Meh
If you have any suggestions, want us to feature an article, or list a data engineering job, hit us up! We would love to include it in our next edition😎
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)