
MDS Newsletter #78

The NEW edition of the Modern Data Stack Newsletter is here! Listen in on our latest podcast episode where we go head-to-head on the ultimate data question: Where does Modern Data Stack fail to deliver? Also, learn about how Lambda and Kappa Architecture for real-time processing differ in designs and strengths!
Modern Data Show S02 E04
S02E05: What's Fundamentally Wrong with Modern Data Stack with Lauren Balik, Owner at Upright Analytics: In this episode of Modern Data Show, Lauren Balik discusses why she believes the modern data stack is flawed and the three factors that affect the cost of a data platform. She compares building versus buying a data platform, and talks about why she thinks there will be no future consolidation in the modern data stack and the role that large language models such as GPT-3 will play.
You can listen to this episode on Spotify, YouTube, Google Podcast, Apple Podcast and Amazon Music.

Featured tools of the week
- Vero is a data-driven email marketing tool. It allows online businesses to use customer behaviour to send email marketing campaigns that convert. Tracking your customers' actions across your website, app or product, the Vero API can collect data in real time.
- Promethium focuses on helping organizations break free from the inefficient data relay holding them back. They have invented the future of data analytics with a solution that prioritizes fast access to trusted answers in minutes instead of months. With Promethium, the customers reduce project backlogs, decrease the number of tools they use from many to one, gain access to current data without moving it and meet business needs by reducing delays in answering pressing business questions without relying on extensive integration projects.
Featured stack of the week
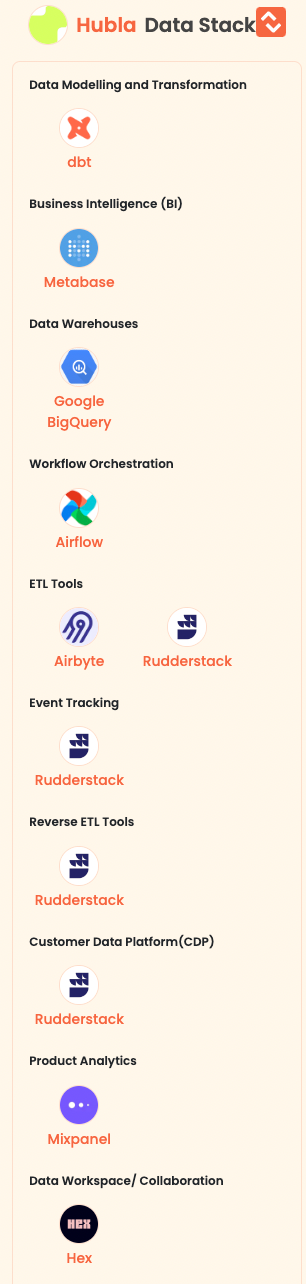
- Hubla enables creators to run their own paid community by providing a smart and fast payment and member management platform. It is a solution for content creators to create their digital communities.
Here are the data tools of Hubla:
Good reads and resources
- Data processing architectures — Lambda vs Kappa for Big Data: This article is written by Ayush Dixit, who discusses the two architectures used for processing large volumes of data in real-time; Lambda and Kappa. The Lambda Architecture has three layers - batch layer, speed layer, and serving layer - to process historical and real-time data and provide queryable views. The Kappa Architecture eliminates the batch layer and uses a stream processing system to store and process real-time data. Both architectures have their strengths and weaknesses and are suited for different scenarios. Lambda is ideal for historical data analysis, while Kappa is better suited for real-time insights.
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh: This article is written by Zhamak Dehghani whose concept of a data mesh platform involves a distributed data architecture under centralized governance and standardization. The platform comprises independent cross-functional teams that own distributed data products, which are oriented around domains and have embedded data engineers and data product owners. Common data infrastructure is used as a platform to host, prep and serve data assets, enabling interoperability and self-serve capabilities. The data lake and data warehouse are nodes on the mesh, with their tooling and pipeline considered implementation details. The paradigm shift involves treating domain data products as a first-class concern, with data lake tooling and pipeline as a second-class concern. This shift necessitates a new set of governing principles and language.
Upcoming data events, webinars and summits
- Join this live webinar on "Moneyball: How the Texas Rangers use low-code data engineering and analytics to identify MVPs" on Thursday, April 6th at 9 am PT | 12 pm ET to learn how the Rangers’ data team overcame the challenges of technical resource constraints and the complexities of scaling real-time data pipelines with Prophecy’s low-code data engineering platform.
Register for the event here. - Join this Hybrid summit "Big Data Technology Warsaw Summit 2023" from Tuesday, March 28th. You can choose whether you prefer to watch the conference online or join them in person in Warsaw.
Register for the event here.
Data startup funding news
Sifflet secures $12.8 M in Series A financing to put an end to data entropy: Sifflet has successfully closed a $12.8M million Series A funding round led by EQT Ventures, with participation from existing investors. Sifflet raised a Seed round in November 2021 led by Mangrove Capital Partners (Yannick Oswald) with participation from Bessemer Venture Partners (Alex Ferrara).
About Sifflet: It offers a Data Observability platform that aims to enhance Data Quality Monitoring and optimize the resources of Data teams.
Founders: Salma Bakouk, Wissem Fathallah, Wajdi Fathallah
MDS Jobs
- Code.org is hiring Data Analytics Engineer
Location: Remote or US
Stack: AWS, Tableau
Apply here - Aftership is hiring Senior Data Warehouse Engineer
Location: Shenzhen, China
Stack: dbt, Bigquery, Airflow
Apply here - Zebra is hiring Senior Data Engineer
Location: Remote - Austin, or U.S.
Stack: dbt, Snowflake, Kinesis
Apply here
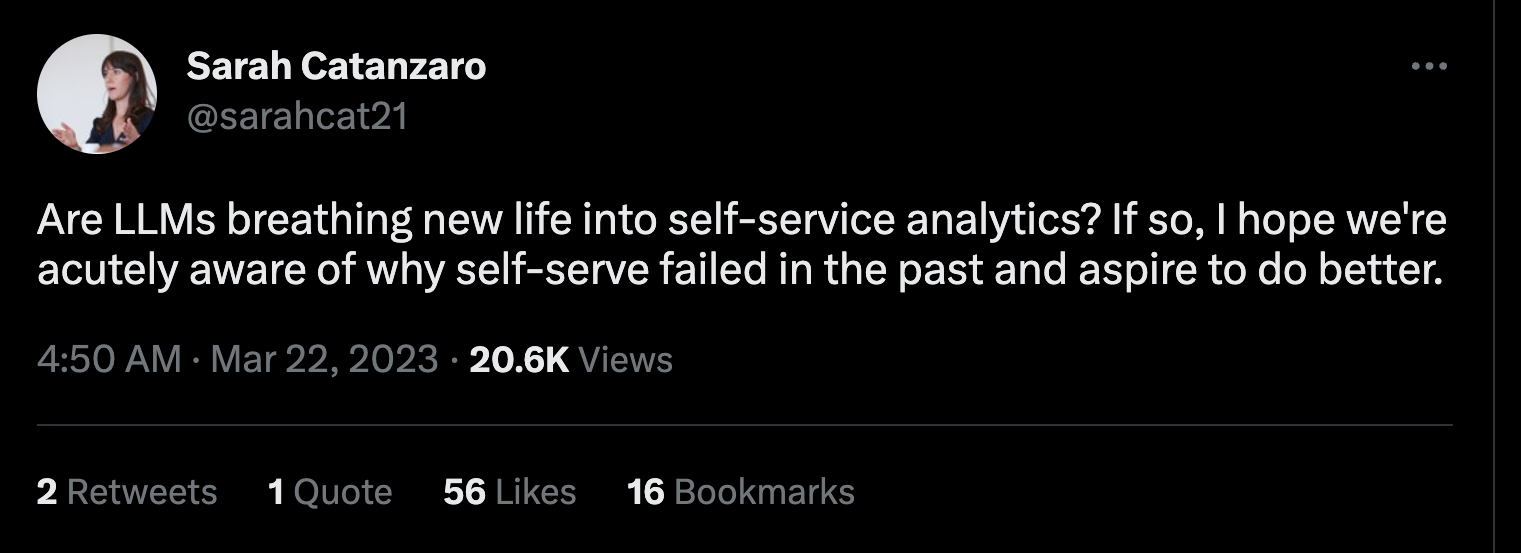
🔥 Trending on Twitter
Just for fun 😀

Are you always hungry for more information and updates about the ever-evolving world of data?
Well, you're in luck! By following us on LinkedIn and Twitter, you'll gain access to all the latest and greatest data content!
But wait, there's more! We want to hear from you - rate us here and let us know how we're doing.
Love it | It's great | Good | Okay-ish | Meh
We welcome any suggestions, articles you would like us to showcase, or data engineering job listings that you may have. Don't hesitate to get in touch with us as and we would be delighted to incorporate your input into our next edition.