
MDS Newsletter #80

Hello there! We are excited to share with you our most recent podcast episode with Murali Kallem, Head of Data Platform at Salesforce, which delves into Salesforce's modernization efforts, migration to Snowflake, and use of cloud-based tools. We also have some exceptional data tools and stacks, recommended reading, upcoming data events, and updates on data startup funding.
Have a read below and enjoy 👇
Modern Data Show S02 E07
S02 E07 Revolutionizing the Data Landscape: Inside Salesforce's modernization journey with Murali Kallem, Head of Office of Data at Salesforce: In the latest episode of the Modern Data Show, Murali Kallem, Head of Office of Data at Salesforce discusses the Snowflake modernization efforts, including migrating to Snowflake and adopting cloud-friendly tools. Murali also covers the importance of vendor support structures for established companies and the consideration of open-source versus commercial offerings.
You can listen to this episode on Spotify, YouTube, Google Podcast, Apple Podcast and Amazon Music.

Featured tools of the week
- Min.io: It is an open-source object storage server with Amazon S3-compatible API. It provides the facility to build cloud-native applications portable across all major public and private clouds. It protects the data against hardware failures using erasure code and bitrot detection.
MinIO has raised a total of $126.3M in funding over 3 rounds. Their latest funding was raised on Jan 26, 2022, from a Series B round. - Data Kitchen: It offers a DataOps platform which enables users to automate and coordinate the people, tools, and environments in any data analytics setup. It performs orchestration, testing, and monitoring to development and deployment of data analytics solutions.
Featured stack of the week
- Health Joy: HealthJoy is a mobile application that maximizes the value of employers’ benefits packages, reclaims HR’s time so they can focus on strategy over administrative tasks, and helps employees achieve better healthcare outcomes.
Here are the data tools of Health Joy:

Good reads and resources
- Snowpark for Python: Best Development Practices: Snowpark, a feature recently added to Snowflake that enables building secure and scalable data pipelines and machine learning workflows within Snowflake. Zdravko Yanakiev, the author of this article, explores best practices for using Snowpark for Python projects, including version control and dependency management tools such as Poetry, and the benefits of using a deterministic, replicable development environment. Yanakiev also discusses using stored procedures to load and preprocess data and train models. Additionally, He describes a workflow and environment separation strategy for collaborative ML projects, using GitLab for version control and CI/CD pipelines, and Snowflake for data warehousing and model deployment. The strategy involves branch protections and variable management on GitLab and role-based access control on Snowflake. He also outlines adding new features and model versions and provides an example CI/CD pipeline that uses Docker images to run jobs in containers.
- GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly: How can GPT-4 can turn complex JSON data into SQL schema or SQL schema updates automatically? Can users paste JSON output from any API into the model and ask it to generate a SQL schema tailored to their destination database? With this guide, tedious and monotonous schema design can be eliminated, and efficiency can be enhanced as explained by Noah Schairer. In an example using Blockstream’s public Bitcoin API, GPT-4 generated a PostgreSQL schema for a response with arrays and nested fields, requiring multiple tables and foreign key references in SQL.
Upcoming data events, webinars and summits
- DataCamp is hosting a live webinar on "The Future of Data Skills: Exploring the Impact of Generative AI" on Thursday, April 13 at 11 am ET. Explore the future of data skills and how generative AI will shift the landscape of data science. The speakers will provide insights into how generative AI can transform the data science workflow, and enable data scientists and teams to be more efficient.
Register for the event here. - Get an insight into data engineering for lakehouse architectures and discover the dos and don'ts of designing and running data pipelines in production by joining the live webinar "Building Production-Ready Data Pipelines on the Lakehouse" at 10:00 AM PT on April 11, 2023. The speakers will also explore the advanced capabilities of Delta Live Tables and Databricks Workflow and show how these powerful solutions work in a live demo
Register for the event here. - Attend this Physical conference "Entropy Data Observability Conference 2023" in London and Paris on April 20th, 2023 and April 27th, 2023 respectively. The goal is to bring together leading industry experts and inspire data practitioners to share their most valuable insights and discuss current trends of the modern data stack.
Register for the event here.
Data startup funding news
- Data infrastructure platform Dozer raises $3 million in seed funding: Dozer is the handiwork of Vivek Gudapuri and Matteo Pelati, who founded the company from their base in Singapore nearly a year ago. It has raised $3 million in seed funding which was led by Sequoia Capital India and Southeast Asia’s Surge, the fundraise also saw participation from Gradient Ventures and January Capital.
About Dozer: implements a Real-Time SQL Engine that connects to any of your data sources, transforms and stores the data in an embedded cache powered by LMDB, automatically creates secondary indexes and instantly generates REST and gRPC APIs. Protobuf and Open API documentation are available out of the box.
MDS Jobs
- GiveDirectly is hiring a Platform Data Engineer
Location: New York, NY (remote)
Stack: Databricks, AWS, Spark, Tableau
Apply here - Eurecia is hiring Data Engineer
Location: France - Toulouse
Stack: DBT, Airbyte, Airflow, BigQuery, Metabase
Apply here - Nutrisense is hiring Data Engineer - DBT, Postgres, BigQuery
Location: Remote - Global
Stack: PosgreSQL, DBT, Python, BigQuery, Metabase, Mixpanel
Apply here
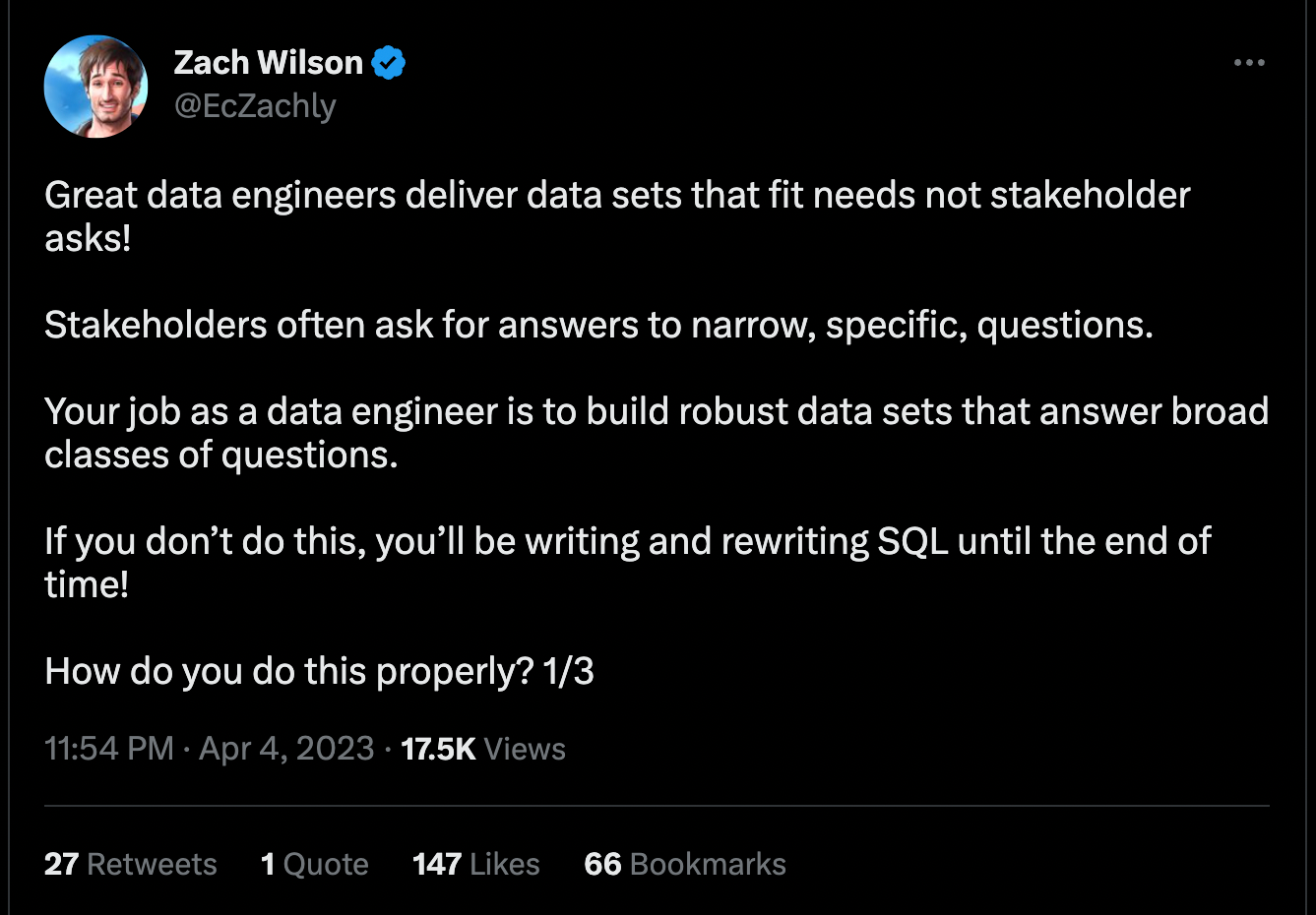
🔥 Trending on Twitter
Just for fun 😀

Do you have an insatiable appetite for the latest developments in the dynamic realm of data? You're in luck! Simply click the "Follow" button on our LinkedIn and Twitter profiles and indulge in the freshest and most cutting-edge content on data.
That's not all! We value your feedback and encourage you to rate us here. Don't be hesitant to share your thoughts on how we're delivering the data goods!
Love it | It's great | Good | Okay-ish | Meh
We welcome your ideas, recommended articles, and job listings pertaining to data engineering. Your input is valuable to us and will be incorporated into our next edition. Please don't hesitate to reach out and share with us.
About Moderndatastack.xyz, we are building a platform to connect members of the data community and educate them on modern data infrastructure and management. We're proud of our platform and invite you to explore it!