
MDS Newsletter #86

🚀 Welcome Aboard the New Edition of the MDS Newsletter! Are you ready to dive into a world of trending data topics, exciting news, and awesome reads? We've got it all here for you, folks!
But first, let's talk about the three incredible events and summits we have coming up. Trust us, you don't want to miss out on these! From networking with industry experts to gaining insights on the latest data trends, these events are a must-attend for anyone in the field.
And have you heard about our Rocketship Awards campaign? It's taking off like a rocket! Companies are posting and reposting about it, and we're getting some serious traction. Don't forget to read the whole newsletter to stay up to date. 👇
Modern Data Show S02 E12
S02 E12 Unveiling Twilio's Data Transformation: A Journey into Modern Data Stack with Don Oriti, Head of Data Platform and Engineering at Twilio: Twilio has built an open source data lake using AWS technologies and DataBricks, processing billions of events daily through their Kafka environment. They aim to provide a cohesive view of data across platforms and enable other businesses to use data wherever they want. Don, the Head of Data Platform and Engineering at Twilio, shares insights into Twilio's data stack in the latest episode of the Modern Data Show. The conversation covers the Twilio data stack, which begins with data ingestion through Kafka or CDC for Aurora databases, followed by storage in S3, high-level aggregation and curation using Spark, and the use of tools such as Kudu, Reverse ETL, data governance, cataloging, and BI tools.
You can listen to this episode on Spotify, YouTube, Google Podcast, Apple Podcast and Amazon Music

Featured tools of the week
- Skyvia: It offers a Universal Cloud Data Platform, which provides data integration, backup, management, and connectivity solutions. Their product is a 100% cloud-based platform that is highly agile and scalable, eliminating the need for manual upgrades or deployment. The platform is designed for ease of use and requires no coding, making it accessible to both IT professionals and business users with no technical skills. Skyvia offers flexible pricing plans for each product, which makes it scalable for businesses of any size, from small startups to enterprise companies.
- Incorta: The Open Data Delivery Platform provided by Incorta offers a solution that aims to streamline and optimize the process of data delivery. By leveraging their innovative smart lakehouse technology, users can experience significant time and cost savings, potentially reaching up to 95%. Their platform is designed to empower IT teams in leading companies, enabling them to deliver analytics with exceptional speed, agility, trust, and simplicity. By providing real-time analytics capabilities, Incorta facilitates informed decision-making and helps companies stay ahead in today's data-driven landscape.
Featured stack of the week
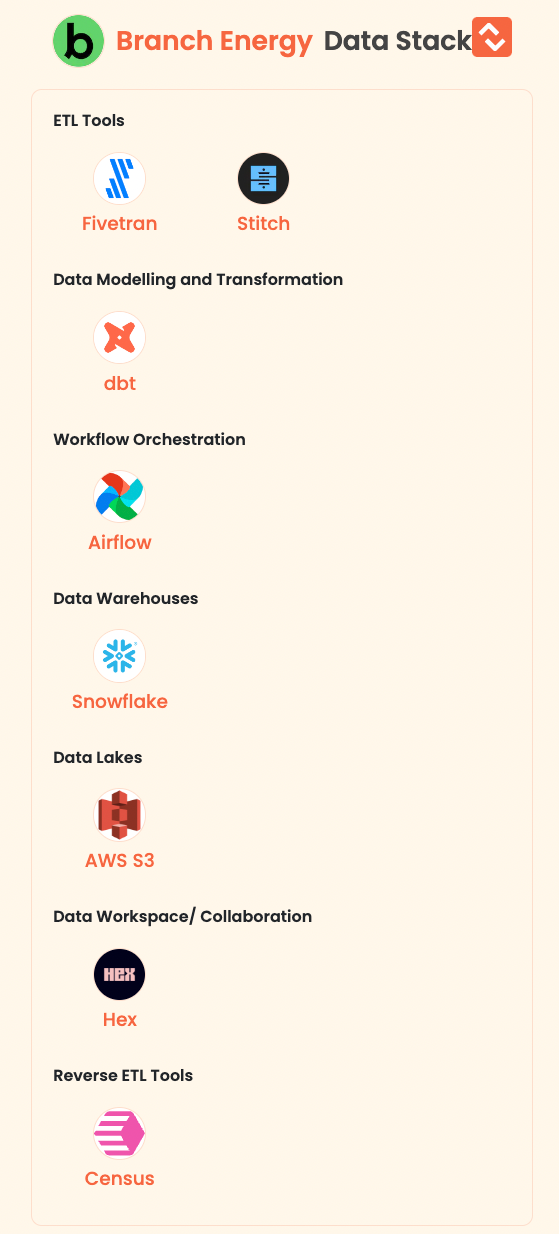
- Branch Energy: Branch Energy is a company dedicated to helping homeowners reduce their energy bills and achieve energy efficiency in their homes. Through their personalized assistance and one-stop solution, they offer a seamless experience for homeowners looking to upgrade their homes and save on energy costs.
Here are the data tools of Branch Energy:
Good reads and resources
- Concepts for Data Engineers: Dimensional Data Modelling: Cassio, a data modeling expert, emphasizes the importance of data modeling in designing and developing databases. Data modeling ensures that data is stored consistently and coherently. One widely used approach in data warehousing and business intelligence is Kimball's dimensional modeling approach. This approach organizes data into fact and dimension tables, enabling efficient querying and analysis. The creation of star and snowflake schemas is emphasized in this approach. The star schema is popular due to its easy-to-understand relationships between the central fact table and surrounding dimension tables, improving performance by reducing the number of joins required to retrieve specific information. On the other hand, the snowflake schema normalizes dimension tables to eliminate redundancy and improve data integrity, making it useful for complex data models with many attributes. However, it may increase query complexity and slower performance compared to the star schema. Understanding the differences between these two approaches is critical in developing an effective data modeling strategy for data warehousing and business intelligence.
- Building a Real-Time Traffic Monitoring Pipeline with Spark Streaming, Kafka, and Time-Series DB: Have you heard about the latest project in data pipeline for traffic monitoring? The article by Aleksander discusses an innovative approach to building a data pipeline that utilizes both batch and real-time processing of data. Aleksander introduces the pipeline components, including Apache Spark for batch processing of historical traffic data, Kafka and Spark for real-time processing of current traffic data, and InfluxDB and PostgreSQL for storing and querying processed data. Additionally, He highlights the importance of using Metabase for creating interactive dashboards that enable visualizing the data and gaining insights. By combining batch and real-time processing, this project offers both historical and real-time insights into traffic conditions, which can help cities and transportation agencies make more informed decisions. Overall, he provides a valuable resource for anyone interested in exploring data pipeline solutions for traffic monitoring.
Upcoming data events, summits and webinars
- Join the Modern Data Stack Summer Social! 🌞 Calling all data leaders! Thoughtspot, dbt Labs, and Fivetran are thrilled to invite you to an unforgettable community event.
📅 Date: Thursday, June 8
⏰ Time: 4pm-7pm PT
📍 Venue: SP2 Kitchen + Restaurant, San Jose, CA
Whether you're a data analyst, scientist, engineer, or enthusiast, this is your chance to connect with like-minded professionals and discuss the latest trends in the modern data stack. Network with industry experts, gain valuable insights and forge meaningful relationships that can fuel your data-driven success. Register now to secure your spot at this must-attend event. - Join the Data Happy Hours powered by 5X on Sunday, May 21, in Bengaluru, Karnataka. Data analysts, scientists, engineers, and enthusiasts are all invited to seize this opportunity to connect with fellow practitioners in the data world. Kindly note that registration approval is required, so act now to secure your spot and ensure you don't miss out on this exciting event. Apply to join today!
- Discover the key to unlocking the full potential of data at the Data Masterclass Europe 2023 in Berlin, taking place from 21st to 23rd June. This immersive event offers three power-packed days that will fast-track your journey to data mastery. Designed exclusively for Data and AI Leaders, this unique training program will equip you with the skills and knowledge needed to harness the power and value of data at scale. Don't miss this opportunity to grow and succeed in the world of data. Secure your spot today!
MDS Jobs
- Windriver is hiring Senior Data Developer
Location: USA (Alameda, CA or Remote)
Stack: dbt, Looker, Fivetran, Snowflake, Datafold, Python
Apply here - Nutrisense is hiring Senior Data Engineer
Location: Remote
Stack: DBT, Airbyte, Stitch, Supermetrics, GCP, Postgres, Python, JS
Apply here - Thaloz is hiring Data Engineer
Location: USA
Stack: DBT, Python, SQL, and AWS or GC
Apply here
🔥 Trending on Twitter

Just for fun 😀

Are you always hungry for more information and updates about the ever-evolving world of data?
Well, you're in luck! By following us on LinkedIn and Twitter, you'll gain access to all the latest and greatest data content!
But wait, there's more! We want to hear from you - rate us here and let us know how we're doing.
Love it | It's great | Good | Okay-ish | Meh
We welcome any suggestions, articles you would like us to showcase, or data engineering job listings that you may have. Don't hesitate to get in touch with us and we would be delighted to incorporate your input into our next edition.
About Moderndatastack.xyz - We're building a platform to bring together people in the data community to learn everything about building and operating a Modern Data Stack. It's pretty cool - do check it out :)